Deep Crossing 模型
Shan Y, Hoens T R, Jiao J, et al. Deep crossing: Web-scale modeling without manually crafted combinatorial features[C]//Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016: 255-262.
微软在2016年提出的Deep Crossing模型是第一次深度学习架构在推荐系统中的完整应用。下图是模型的架构。
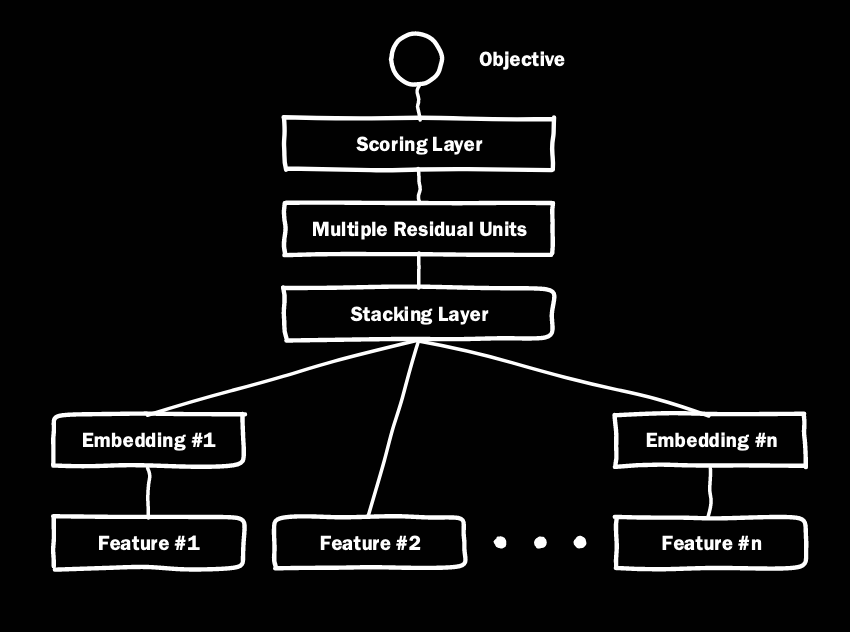
输入特征分为类别特征,数值型特征。类别型特征可以通过onehot或multihot编码生成特征向量,数值型特征可以直接拼接进特征向量中。在输入所有特征向量后,deep crossing模型进行CTR预估。
解决的问题
- 离散型特征向量编码后过于稀疏,该模型解决了稀疏特征向量稠密话的问题。
- 解决特征自动交叉组合的问题。
- 在输出层中达成问题设定的优化目标。
架构介绍
架构包括embedding, stacking, multiple residual unit, scoring四层。
- Embedding层:
将输入的特征向量转化成稠密的嵌入向量。经典结构以全连接层为主,但现在有word2vec,graph embedding等多种不同的embedding方式。(只有离散型特征向量需要embedding, 数值型特征直接进入stacking层)。 - Stacking层:
把所有特征拼接在一起。 - Multiple Residual Unit层:
主要结构是MLP。Deep Crossing使用多层残差网络作为MLP的具体实现。下图是残差单元的具体实现。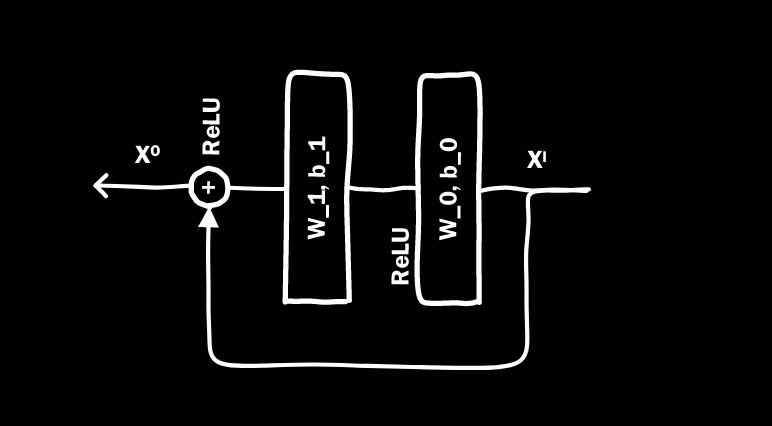
- Scoring层:
逻辑回归(sigmoid)或softmax模型。
NeuralCF 模型
He X, Liao L, Zhang H, et al. Neural collaborative filtering[C]//Proceedings of the 26th international conference on world wide web. 2017: 173-182.
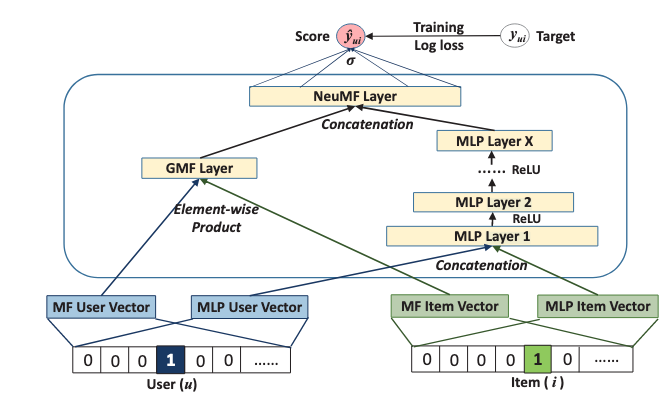
Neural Collaborative Filtering,通常简称为 NCF,是 2017 年非常有代表性的一篇推荐模型工作。它最核心的出发点是:传统矩阵分解通常使用用户向量和物品向量的内积来建模交互关系,但“内积”本身是一种比较强的结构假设,它虽然简单高效,却未必足够灵活。既然深度学习已经在视觉、语音、NLP 中证明了强大的非线性表达能力,那么在推荐问题里,我们是否也可以用神经网络来学习用户和物品之间更复杂的交互函数?
NCF 就是在这个思路下提出的。
解决的问题
- 传统矩阵分解把用户和物品的匹配关系限制为向量内积,表达形式较单一。
- 用户兴趣和物品属性之间往往存在复杂的非线性交互,单纯内积不容易充分刻画。
- 希望在协同过滤框架下,引入深度神经网络自动学习更灵活的用户-物品交互函数。
一、为什么要从矩阵分解走向 NCF
在最经典的隐语义模型里,用户 u 和物品 i 分别对应一个隐向量:
p_uq_i
它们的匹配分数通常写成:
ŷ_ui = p_u^T q_i
这个形式非常经典,也非常有效,因为它把推荐问题转化成了“两个低维向量是否相似”。
但它也有明显限制:用户和物品之间的交互形式被固定成了双线性内积。换句话说,无论用户偏好有多复杂,模型最终都只能通过“对应维度相乘再求和”的方式表达。
NCF 的作者认为,这种假设可能过于刚性。真实场景里,用户和物品之间的匹配关系很可能不是简单线性结构,而是某种更复杂的非线性函数:
ŷ_ui = f(u, i | Θ)
其中 f 由神经网络来学习,Θ 是模型参数。
所以如果用一句话概括 NCF 的思想,就是:
- 用神经网络替代固定的内积函数
- 让模型自己学习“用户向量和物品向量应该如何交互”
二、整体思路
NCF 的基本流程并不复杂,可以概括为四步:
- 为用户和物品分别学习 embedding
- 将用户 embedding 和物品 embedding 送入交互层
- 用神经网络学习高阶非线性交互
- 输出用户对物品的偏好分数
和很多后来的推荐模型相比,NCF 的结构其实非常干净。它并不直接处理特别复杂的多域特征,而是聚焦在最基本的协同过滤设定:
- 输入只有用户 ID 和物品 ID
- 每个用户、物品都映射成一个稠密向量
- 通过不同交互方式预测用户是否会点击、购买或评分
NCF 论文中最重要的并不是一个单独模型,而是一组逐步递进的结构:
- GMF
- MLP
- NeuMF
可以把它们理解为从“矩阵分解的神经化版本”一步步走向“融合线性匹配和非线性匹配”的过程。
三、GMF:Generalized Matrix Factorization
GMF 可以看作是对传统矩阵分解的一种神经网络化改写。
在传统矩阵分解中,用户 u 和物品 i 的匹配分数为:
ŷ_ui = p_u^T q_i = Σ_k p_uk q_ik
而在 GMF 中,作者先保留“按元素乘积”这个交互思想:
φ_GMF = p_u ⊙ q_i
其中 ⊙ 表示逐元素乘法。也就是说,第 k 个维度的交互结果为:
p_uk q_ik
然后不再直接把这些维度简单求和,而是再接一个输出层:
ŷ_ui = σ(h^T (p_u ⊙ q_i))
其中:
h是输出层参数σ是 sigmoid 函数
这样看起来只是“小改”,但意义很重要。传统矩阵分解相当于默认每个维度的权重都一样,而 GMF 允许模型进一步学习不同隐维度在最终预测中的重要性。
因此可以把 GMF 理解成:
- 保留矩阵分解中“逐维匹配”的思想
- 但把最终的固定求和替换成可学习的加权输出
它仍然偏向“线性式交互”,但已经开始摆脱经典矩阵分解那种完全固定的匹配方式。
四、MLP:用多层感知机建模非线性交互
如果说 GMF 还是在矩阵分解附近做改造,那么 MLP 分支就更激进一些。它不再强调“逐元素乘积”,而是直接把用户和物品 embedding 拼接起来,再交给多层感知机学习:
z_1 = [p_u ; q_i]
z_2 = a_2(W_2^T z_1 + b_2)
z_3 = a_3(W_3^T z_2 + b_3)
...
z_L = a_L(W_L^T z_{L-1} + b_L)
最后输出预测分数:
ŷ_ui = σ(h^T z_L)
这里最关键的变化在于:
- GMF 的交互方式是显式设计好的,即逐元素乘法
- MLP 不再预设交互形式,而是让网络在多层非线性变换中自动学习
从表示学习角度看,MLP 给了模型更强的函数逼近能力。理论上,只要网络足够深、参数足够充分,它就可以拟合比内积复杂得多的用户-物品交互模式。
不过,MLP 也带来一个代价:模型虽然更灵活,但可解释性更弱,而且训练难度通常也会高于 GMF。
五、NeuMF:把 GMF 和 MLP 融合起来
作者进一步发现,GMF 和 MLP 其实各有优势:
- GMF 擅长保留矩阵分解式的线性匹配信息
- MLP 擅长学习复杂的非线性交互
所以最自然的想法就是把它们融合起来,这就是 NeuMF(Neural Matrix Factorization)。
NeuMF 的结构是:
- 用户和物品分别进入 GMF 分支
- 用户和物品也分别进入 MLP 分支
- 两个分支各自产生一个高层表示
- 把两个表示拼接,再送入最终输出层
形式上可以写成:
φ_GMF = p_u^G ⊙ q_i^G
φ_MLP = MLP([p_u^M ; q_i^M])
φ_NeuMF = [φ_GMF ; φ_MLP]
ŷ_ui = σ(h^T φ_NeuMF)
这里要注意,GMF 分支和 MLP 分支通常使用不同的 embedding 参数,也就是:
p_u^G, q_i^Gp_u^M, q_i^M
这样做的原因是,两条分支建模的交互模式不同,如果强行共享 embedding,反而可能限制它们各自的表达能力。
NeuMF 可以理解成一种“混合专家”的雏形:
- 一部分参数负责学习类似矩阵分解的结构化交互
- 另一部分参数负责学习更自由的非线性关系
- 最终再把二者融合起来做预测
这也是 NCF 论文里效果最好的主模型。
六、训练方式
NCF 主要考虑的是隐式反馈场景,例如:
- 点击
- 购买
- 收藏
- 观看
在这类任务里,我们通常只知道用户“做了什么”,而不知道用户“明确不喜欢什么”。因此训练时往往要做负采样,也就是:
- 用户交互过的物品作为正样本
- 用户未交互的物品中随机采样一部分作为负样本
在损失函数上,论文主要采用的是二分类学习目标。输出经过 sigmoid 后,可以用交叉熵来优化用户对物品的点击或偏好概率。
直观上就是让模型学会:
- 正样本的预测分数更高
- 负样本的预测分数更低
此外,作者还提出了一个很实用的训练技巧:可以先分别预训练 GMF 和 MLP,再把它们的参数初始化到 NeuMF 中继续联合训练。这样通常会比从随机初始化直接训练 NeuMF 更稳定。
七、NCF 和矩阵分解的关系
理解 NCF 时,一个特别重要的问题是:它和矩阵分解到底是什么关系?
可以这样看:
- 矩阵分解是最经典的协同过滤隐向量模型
- GMF 是对矩阵分解的神经网络化扩展
- MLP 是完全用深度网络重新定义用户-物品交互函数
- NeuMF 则把这两种思路融合起来
所以 NCF 并不是“推翻矩阵分解”,而是在矩阵分解的基础上继续往前走了一步。
如果只保留最简单的交互形式,那么 NCF 可以退化到类似矩阵分解的结构;但如果给它更强的非线性网络,它又可以学习比矩阵分解更复杂的模式。
八、优点与局限
NCF 的优点很明显:
- 模型结构清晰,容易理解
- 直接把深度学习引入协同过滤交互建模
- 比固定内积更灵活,表达能力更强
- NeuMF 同时结合了线性匹配与非线性匹配信息
但它也有一些局限:
- 输入仍然主要是用户 ID 和物品 ID,侧信息利用不充分
- 如果数据量不够大,复杂的 MLP 分支容易过拟合
- 相比传统矩阵分解,训练成本和调参复杂度更高
- 对工业级推荐系统来说,它更像是重要起点,而不是最终形态
后续很多模型,例如 Wide & Deep、DeepFM、DIN、DCN 等,都在更丰富的特征输入和更复杂的交互建模上继续发展。但从历史脉络上看,NCF 非常关键,因为它清楚地提出了一个问题:
- 用户和物品之间的交互函数,为什么一定只能是内积?
九、小结
NeuralCF 的核心思想可以概括成三句话:
- 传统协同过滤中的内积函数不一定足够表达复杂偏好关系。
- 可以用神经网络来学习用户和物品之间的非线性交互函数。
- 通过融合 GMF 和 MLP,NeuMF 同时保留了矩阵分解式交互与深度非线性表达能力。
如果说 Deep Crossing 解决的是“多特征输入如何通过深层网络自动组合”的问题,那么 NCF 关注的则是另一个更基础的问题:
- 在最纯粹的用户-物品协同过滤场景里,交互函数本身应当如何设计?
这也是它在推荐系统发展史上非常有代表性的原因。
PNN 模型
Qu Y, Cai H, Ren K, et al. Product-based neural networks for user response prediction[C]//2016 IEEE 16th international conference on data mining (ICDM). IEEE, 2016: 1149-1154.
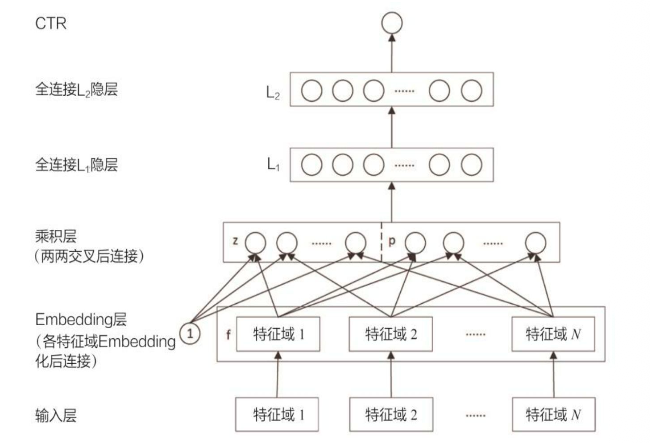
PNN 全称是 Product-based Neural Network。它是 CTR 预估领域很有代表性的一个模型,因为它抓住了一个非常关键的问题:
- embedding 之后直接把所有特征拼接起来,再交给 MLP,当然也能学习交互
- 但这种交互是“隐式”学习出来的,不一定高效,也不一定足够稳定
PNN 的核心想法是:
- 既然点击率预估里最重要的信息之一就是不同 field 之间的组合关系
- 那么不如在 embedding 层之后,先显式做一次乘积交互
- 再把这些交互结果送进 DNN
这就是 PNN 相比 Deep Crossing 最关键的区别。
解决的问题
- 仅仅做 embedding 拼接,模型需要靠后续 MLP 自己去摸索特征交叉关系。
- CTR 场景中的很多有效信号都来自 field 与 field 之间的组合,而不是单一特征。
- 希望在进入深层网络之前,先显式构造二阶交互,让后续网络学习更容易。
一、PNN 的整体结构
如果从结构上看,PNN 和 Deep Crossing 很像,主要也包括下面几层:
- 输入层
- Embedding 层
- Product Layer
- 全连接神经网络层
- 输出层
它和 Deep Crossing 最大的不同在于第三层。
在 Deep Crossing 中,embedding 之后通常直接做拼接,也就是 stacking;而在 PNN 中,embedding 之后不会立刻简单拼接,而是先进入 Product Layer,通过乘积操作显式建模特征交互。
所以可以把 PNN 理解成:
- 前半部分负责把稀疏离散特征映射成稠密向量
- 中间的 Product Layer 负责显式做特征交叉
- 后半部分的 MLP 负责在交叉结果基础上继续学习更高阶模式
二、为什么需要 Product Layer
在推荐系统或广告点击率预估中,输入通常不是一个单一特征,而是很多 field 的组合,例如:
- 用户性别
- 年龄段
- 城市
- 广告 ID
- 广告类别
- 设备类型
- 时间段
这些 field 经过 embedding 之后,会变成多个低维向量:
e1e2e3...em
其中 m 是 field 数量。
如果像普通 DNN 一样,直接把它们拼接:
z = [e1 ; e2 ; ... ; em]
那么模型确实可以学习交叉,但这种交叉需要在后续多层非线性变换中间接形成。
PNN 认为,这样做太“绕”了。因为很多关键模式本来就是显式的特征组合,例如:
- 某类用户是否更偏好某类广告
- 某个广告在某个时段是否更容易被点击
- 某种设备环境下某类素材是否更有效
这些关系天然就是 field 与 field 的交互。因此更合理的方式是:
- 先明确构造交叉信号
- 再把这些信号交给 DNN
三、Embedding Layer
PNN 的 embedding 层和其他深度推荐模型差别不大。
假设第 i 个 field 经过 embedding 后得到向量:
ei ∈ R^d
其中 d 是 embedding 维度。
这样,一个样本最终就会得到 m 个 embedding 向量。到这里为止,PNN 和普通的 embedding + MLP 结构还没有本质区别。真正的创新在于下一层的 Product Layer。
四、Product Layer
Product Layer 是 PNN 的核心。
它的目标不是简单把 embedding 拼起来,而是要同时保留两类信息:
- 线性信息
- 乘积交互信息
因此从结构上看,Product Layer 通常可以理解为由两部分组成:
z:线性部分,保留原始 embedding 的信息p:乘积部分,显式表示 field 与 field 之间的交互
最终,这两部分会一起输入到后面的全连接层。
你可以把这一层想象成:
z告诉模型“每个 field 本身是什么”p告诉模型“这些 field 之间是怎么相互作用的”
这也是 PNN 和单纯 DNN 相比最重要的建模增强。
五、Product Layer 的两种主要形式
PNN 论文中主要讨论了两种 product 形式:
- IPNN:Inner Product-based Neural Network
- OPNN:Outer Product-based Neural Network
两者的区别在于,它们对两个 embedding 向量之间的交互保留了多少信息。
六、IPNN:内积式交互
在 IPNN 中,两个 field 的交互由内积表示:
pij = <ei, ej>
也就是说,第 i 个 field 和第 j 个 field 的关系,被压缩成一个标量。
如果一共有 m 个 field,那么就可以得到所有两两组合的交互:
(e1, e2)(e1, e3)...(em-1, em)
直观上,IPNN 的含义是:
- 如果两个 field 的 embedding 在隐空间中更接近,那么它们的内积更大
- 内积越大,说明模型认为这两个 field 的组合关系越重要
这种方式的优点是很轻量,而且和 FM 的思想很接近,因为 FM 也是通过隐向量内积来表达特征交叉。
所以从直觉上看,IPNN 其实是在做一件事:
- 用向量相似性来表达不同 field 之间的交互强度
七、OPNN:外积式交互
相比 IPNN,OPNN 更进一步。它不是把两个 embedding 的关系压缩成一个标量,而是计算外积:
pij = ei ej^T
如果 ei ∈ R^d 且 ej ∈ R^d,那么外积结果是一个 d × d 的矩阵。
这个矩阵会保留更丰富的交互信息,因为:
- 内积只能得到一个整体匹配分数
- 外积则保留了“第 a 维和第 b 维如何相互作用”的细粒度结构
因此,OPNN 的表达能力通常比 IPNN 更强,但代价也很明显:
- 计算量更大
- 参数量更大
- 实现更复杂
所以可以简单理解为:
- IPNN 更轻量,更容易训练
- OPNN 更强,但更重
这也是 PNN 中很典型的表达能力与效率之间的权衡。
八、PNN 为什么比普通 DNN 更适合 CTR 预估
CTR 场景有一个非常重要的特点:很多有效信号天然来自组合关系,而不是单个特征本身。
例如:
- 某类用户对某类广告更敏感
- 某广告在某时间段点击率更高
- 某设备环境下某类素材表现更好
如果只用普通 DNN:
- 模型必须通过后续多层网络慢慢学出这些交叉关系
而 PNN 则是:
- 在进入 DNN 之前,就先把这些乘积关系显式做出来
这样一来,后面的 MLP 不需要从零开始摸索“谁和谁要交互”,而是直接在已有交叉特征的基础上继续建模。因此在 CTR 任务中,PNN 往往比简单的 embedding + MLP 更有针对性。
Wide & Deep 模型
Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.
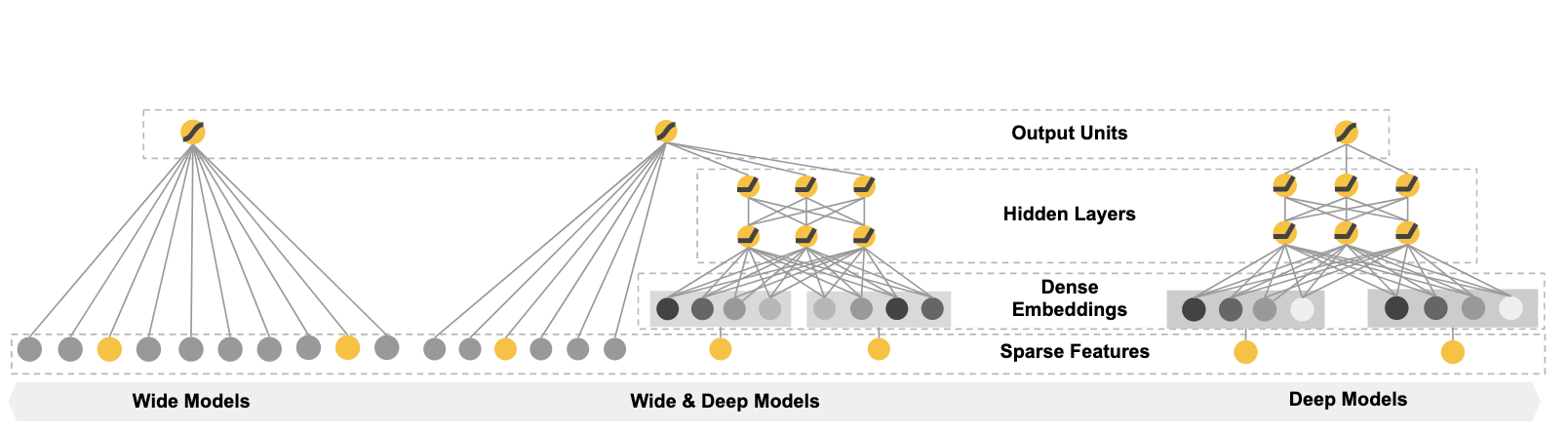
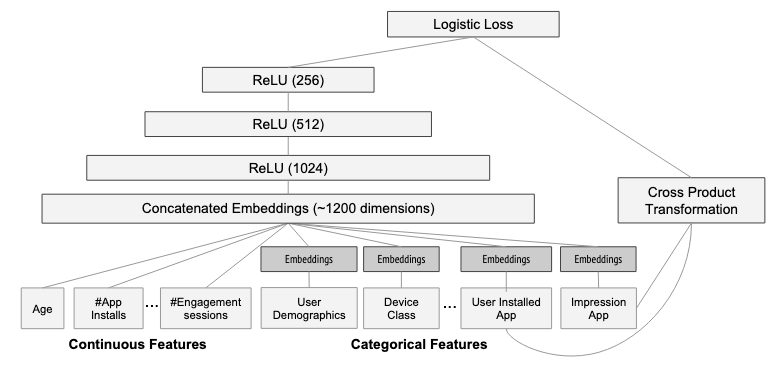
Wide & Deep 是 Google 在 2016 年提出的经典推荐模型。它之所以重要,不是因为结构特别复杂,而是因为它非常准确地抓住了推荐系统里的一个核心矛盾:
- 我们希望模型能够“记住”历史上出现过的高价值规则
- 也希望模型能够对没见过的新组合进行“泛化”
传统的线性模型在“记忆”方面很强,因为它能够非常直接地学习人工设计好的交叉特征;但它的泛化能力有限。纯深度模型则恰好相反,能通过 embedding 学到一定泛化能力,但对一些明确的、稀疏的规则模式不一定学得足够稳定。
Wide & Deep 的核心思想就是把这两类能力放进同一个模型里:
- Wide 部分负责 memorization,也就是记忆能力
- Deep 部分负责 generalization,也就是泛化能力
解决的问题
- 线性模型擅长记住显式规则,但难以对未见组合泛化。
- 深度模型有更强的表示学习能力,但不一定能稳定捕捉那些稀疏而明确的组合规则。
- 推荐系统既需要记忆历史经验,也需要对新样本、新组合做合理推断。
一、为什么“记忆”和“泛化”要分开看
在推荐和广告任务里,很多有效信号其实可以分成两类。
第一类是“记忆型”信号,例如:
- 安装过某类 App 的用户更容易点击某类广告
- 某城市、某设备、某时间段与某个广告位组合时点击率特别高
这种模式往往是明确的、稀疏的,而且很像规则。一旦数据中真的出现过多次,线性模型就能把它们记得很好。
第二类是“泛化型”信号,例如:
- 虽然用户没看过这个广告,但他看过相似类别广告
- 虽然某个组合没在训练中高频出现,但相关特征在 embedding 空间里很接近
这种模式就更适合交给深度模型去学习。
Wide & Deep 的出发点正是:
- 单独依赖线性模型不够
- 单独依赖 DNN 也不够
- 更合理的方式是把两者结合起来
二、整体结构
Wide & Deep 的结构很直观,由两部分并联组成:
- Wide 侧
- Deep 侧
最后把两部分的输出加到一起,再经过 sigmoid 或 softmax 得到最终预测结果。
从结构上理解,它像是:
- 一条“规则记忆通路”
- 一条“表示学习通路”
这两条通路共享同一个任务目标,但分别承担不同职责。
三、Wide 部分:负责记忆
Wide 部分本质上是一个广义线性模型,可以写成:
y_wide = w^T x + b
这里的 x 不只是原始稀疏特征,还通常包括人工构造的交叉特征,例如:
AND(user_installed_app = TikTok, impression_app = YouTube)AND(gender = male, category = sports)
这种交叉特征通常可以通过笛卡尔积、哈希交叉等方式构造出来。
Wide 部分的优势在于:
- 对显式交叉非常敏感
- 对训练中高频出现的规则能学得很准
- 结果相对更可解释
但它的问题也很明显:
- 人工交叉特征设计成本高
- 对没见过的组合泛化较弱
所以它很适合做“记忆”,但不适合单独承担整个推荐任务。
四、Deep 部分:负责泛化
Deep 部分则是一条典型的 embedding + MLP 结构。
首先,离散特征会被映射成 embedding:
- 用户特征 embedding
- 物品特征 embedding
- 上下文特征 embedding
然后这些 embedding 被拼接起来,送入多层全连接网络:
a^(l+1) = f(W^(l) a^(l) + b^(l))
通过这种多层非线性变换,模型可以学习到:
- 特征之间更抽象的组合关系
- 相似特征之间的共享表示
- 训练集中未充分出现过的模式
Deep 部分最重要的能力就是泛化。
它不需要显式写出“某用户属性和某广告属性应该如何交叉”,而是通过 embedding 空间中的相似性,把不同组合联系起来。
五、Wide 与 Deep 如何融合
Wide & Deep 的最终输出可以理解为:
y = σ(y_wide + y_deep)
也就是说:
- Wide 分支给出一部分线性/规则型判断
- Deep 分支给出一部分非线性/泛化型判断
- 两者共同决定最终结果
这种融合方式非常简单,但很有效。它的关键不是复杂的融合技巧,而是明确地让两种不同归纳偏置同时存在。
换句话说,Wide & Deep 不是要让一个模型同时“既像线性模型又像 DNN”,而是干脆保留两个分支,让它们各司其职。
六、为什么这个模型在推荐里非常重要
Wide & Deep 的价值在于,它把很多工业推荐系统早就知道的一个经验显式写进了模型结构里:
- 某些模式非常像规则,应该被记住
- 某些模式更依赖表示学习,应该被泛化
对于推荐系统来说,这特别重要,因为真实数据往往同时具有:
- 稀疏性
- 长尾性
- 新组合不断出现
如果只有 wide:
- 模型会过于依赖已见规则
如果只有 deep:
- 模型可能对明确的稀疏规则记忆不够稳
Wide & Deep 刚好在这两者之间找到一个平衡点。
七、和前面几个模型的关系
把 Wide & Deep 和前面几个模型放在一起看,会更容易理解它的定位。
1. 和 Deep Crossing 的关系
Deep Crossing 更强调:
- embedding 后直接接深层网络
- 依靠 DNN 自动学习特征组合
Wide & Deep 则认为:
- 只靠深层网络还不够
- 一些显式规则值得单独保留一条 wide 分支
所以:
- Deep Crossing 更偏“纯深度”
- Wide & Deep 更偏“线性规则 + 深度学习混合”
2. 和 PNN 的关系
PNN 是在 deep 分支内部显式加入 Product Layer,强调 embedding 之间的交互。
Wide & Deep 的关注点则不同:
- 它不是在 DNN 内部细化交互方式
- 而是在模型顶层直接并联一条线性记忆分支
所以两者虽然都在解决“特征交互”问题,但切入点不同:
- PNN 强调在 deep 网络内部做显式交叉
- Wide & Deep 强调把“记忆”和“泛化”两种能力拆开建模
八、优点与局限
Wide & Deep 的优点主要有:
- 结构简单清晰,工程上容易落地
- 同时兼顾显式规则记忆和深度表示学习
- 在工业推荐场景中非常实用
- 为很多后续模型提供了重要设计思路
它的局限也比较明显:
- Wide 部分仍然依赖人工交叉特征设计
- 特征工程成本较高
- wide 和 deep 的交互方式比较简单,通常只是最后相加
- 对更复杂的自动特征交叉能力仍有限
这也解释了为什么后续会出现 DeepFM、DCN、xDeepFM 等模型。它们本质上都在尝试进一步回答一个问题:
- 能不能把“记忆”和“泛化”结合得更自然,同时减少人工交叉特征设计?
九、小结
Wide & Deep 的核心思想可以概括成三句话:
- 线性模型擅长记住显式规则,DNN 擅长学习泛化表示。
- 推荐系统同时需要记忆能力和泛化能力,因此不能只依赖其中一类模型。
- 通过把 wide 分支和 deep 分支联合训练,模型可以同时吸收两类优势。
如果说 Deep Crossing 强调“让深层网络自动学习特征组合”,那么 Wide & Deep 更强调另一件事:
- 有些知识应该被模型记住,有些知识则应该被模型泛化。
这也是它在推荐系统工业实践中极具代表性的原因。
十、进一步:Deep & Cross 模型
Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[M]//Proceedings of the ADKDD’17. 2017: 1-7.
Deep & Cross Network,通常简称为 DCN,可以看作是对 Wide & Deep 的一个很自然的延伸。
Wide & Deep 的问题在于:
- wide 分支确实擅长记忆显式规则
- 但它通常依赖人工构造交叉特征
这在工业上非常有效,但也有明显成本:
- 需要做大量特征工程
- 交叉方式依赖经验
- 很难系统性地覆盖更高阶组合
DCN 的核心思路就是:
- 既然 wide 部分的本质是在做显式交叉
- 那么能不能设计一个神经网络结构,自动完成这种交叉构造
所以可以把 DCN 理解成:
- 用一个可学习的 Cross Network,替代 Wide & Deep 中依赖人工设计的 wide 部分
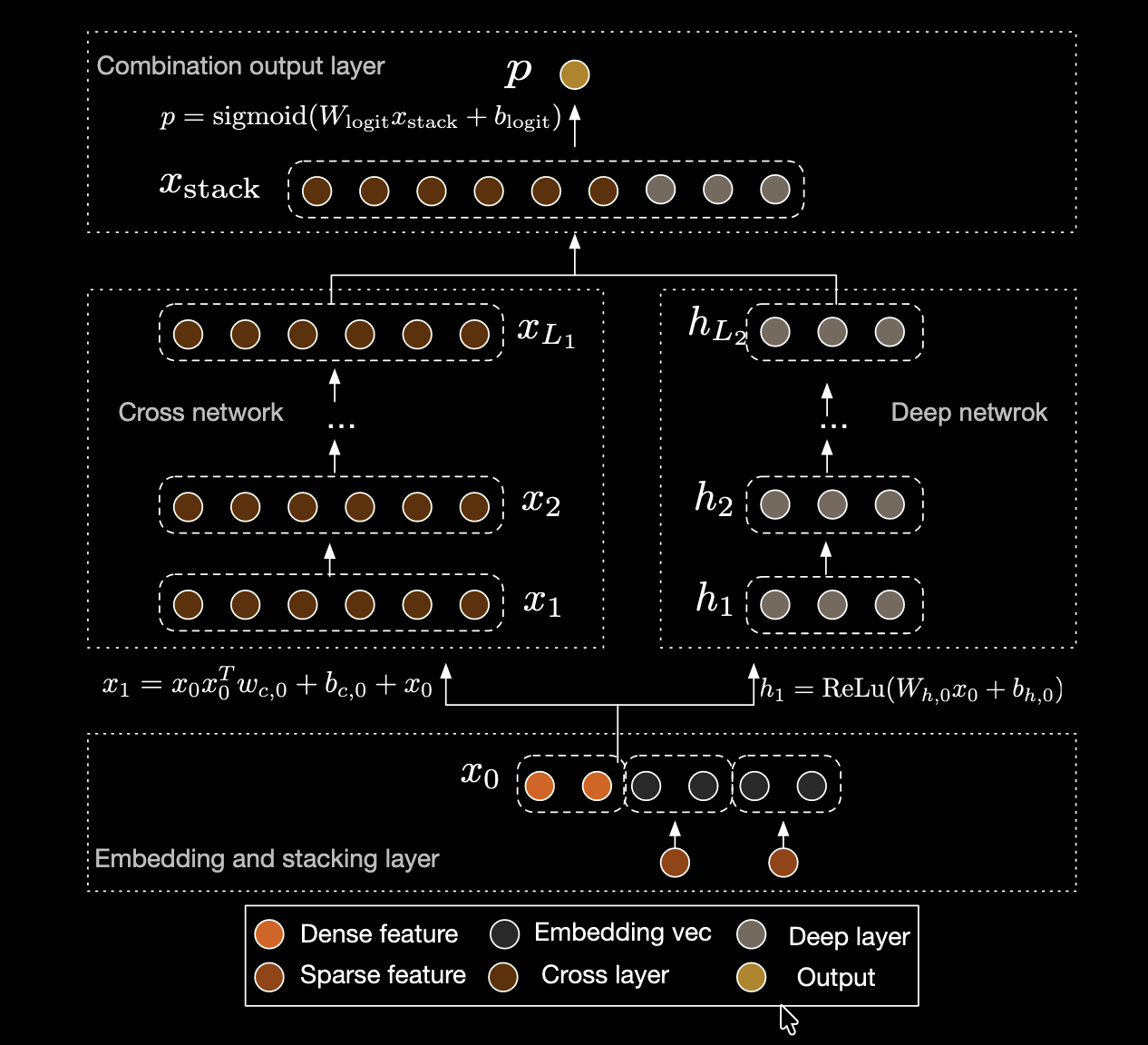
解决的问题
- Wide & Deep 中的 wide 分支依赖人工交叉特征设计,工程成本较高。
- 普通 DNN 虽然可以隐式学习交叉,但对一些低阶或明确的组合关系不一定学习得高效。
- 希望模型能够自动、显式地构造有限阶特征交叉,同时保留 deep 分支的泛化能力。
Cross网络介绍
DCN 的整体结构仍然保留了“并联两路”的思想:
- Cross Network
- Deep Network
其中:
- Cross Network 负责显式构造特征交叉
- Deep Network 负责学习更一般的非线性表示
最后再把两路输出拼接或融合,送入最终输出层。
这意味着 DCN 并不是否定 Deep & Wide,而是对它进行了结构上的升级:
- Wide & Deep:
wide负责人工规则记忆 - DCN:
cross负责自动化特征交叉
Cross Network 的核心公式
设 embedding 和数值特征拼接后的输入向量为:
x0 ∈ R^d
Cross Network 的第 l 层输出记为:
xl
那么它的核心递推公式是:
x_{l+1} = x0 (xl^T wl) + bl + xl
其中:
wl ∈ R^d是第l层的参数向量bl ∈ R^d是偏置项xl^T wl是一个标量
这个公式第一次看会有点怪,但它非常重要,因为它直接体现了 DCN 的建模方式。
可以把它拆开理解:
xl^T wl先把当前层表示压缩成一个标量- 再用这个标量去缩放原始输入
x0 - 最后加上残差项
xl
于是每一层都在做一件事:
- 让原始输入
x0和当前表示xl发生一次显式交互
这就是为什么它叫 Cross Network。
为什么这个公式能产生特征交叉
DCN 最值得理解的地方就在这里。
先看第一层:
x1 = x0 (x0^T w0) + b0 + x0
其中 x0^T w0 是对输入各维度的线性组合。再乘回 x0 之后,就会出现不同维度之间的乘积项。
如果继续往后堆层,比如到第二层、第三层,那么这种“原始输入”和当前表示”的交互会不断叠加,于是模型可以显式构造更高阶特征交叉。
一个非常关键的结论是:
- Cross Network 堆叠
L层时,理论上可以显式建模到L+1阶特征交叉
这和普通 MLP 不一样。
普通 MLP 当然也可能拟合高阶交叉,但那是“隐式”学出来的;而 DCN 的 Cross Layer 是把交叉结构直接写进了网络形式里。