齐夫定理
一个单词出现的频率与它在频率表里的排序成反比。
例如,在英语的 Brown 语料库中,「the」、「of」、「and」是出现频率最高,排序 1、2、3 的单词,分别占整个语料库100万个单词数的 7%、3.6%、2.9%[1]。可见排序第2位「of」的频率大约是第1「the」的1/2,第3的「and」是其 1/3。以此类推,排序第n单词的频率是最常见频率的1/n。最简单的齐夫定律排序遵从一次反比即 1/f 关系。由此可以得到它的等价描述:
在给定语料中,对于任意一个单词,其频率(Frequency)与频率排序(Rank)乘积大致是一个常数,即:Rank * Frequency ≈ Constant
因此虽然语言中的词汇数量是无穷的,无法用任何词典完整收录,但将单词词频降序排列,由齐夫定律可得,越靠后词频越小,趋近于0,平时很难碰到,因此可以尝试词典分词。
切分算法
- 完全切分
- 正向最长匹配
- 逆向最长匹配
- 双向最长匹配
字典树
匹配算法的瓶颈之一在于如何判断集合(词典)中是否含有字符串。
字典树中每条边都对应一个字, 从根节点往下的路径构成一个个字符串。字典树并不直接在节点上存储字符串, 而是将词语视作根节点到某节点之间的一条路径,并在终点节点(蓝色) 上做个标记“该节点对应词语的结尾”。字符串就是一 条路径,要查询一个单词,只需顺着这条路径从根节点往下走。如果能走到特殊标记的节点,则说明该字符串在集合中,否则说明不存在。一个典型的字典树如下图所示所示。
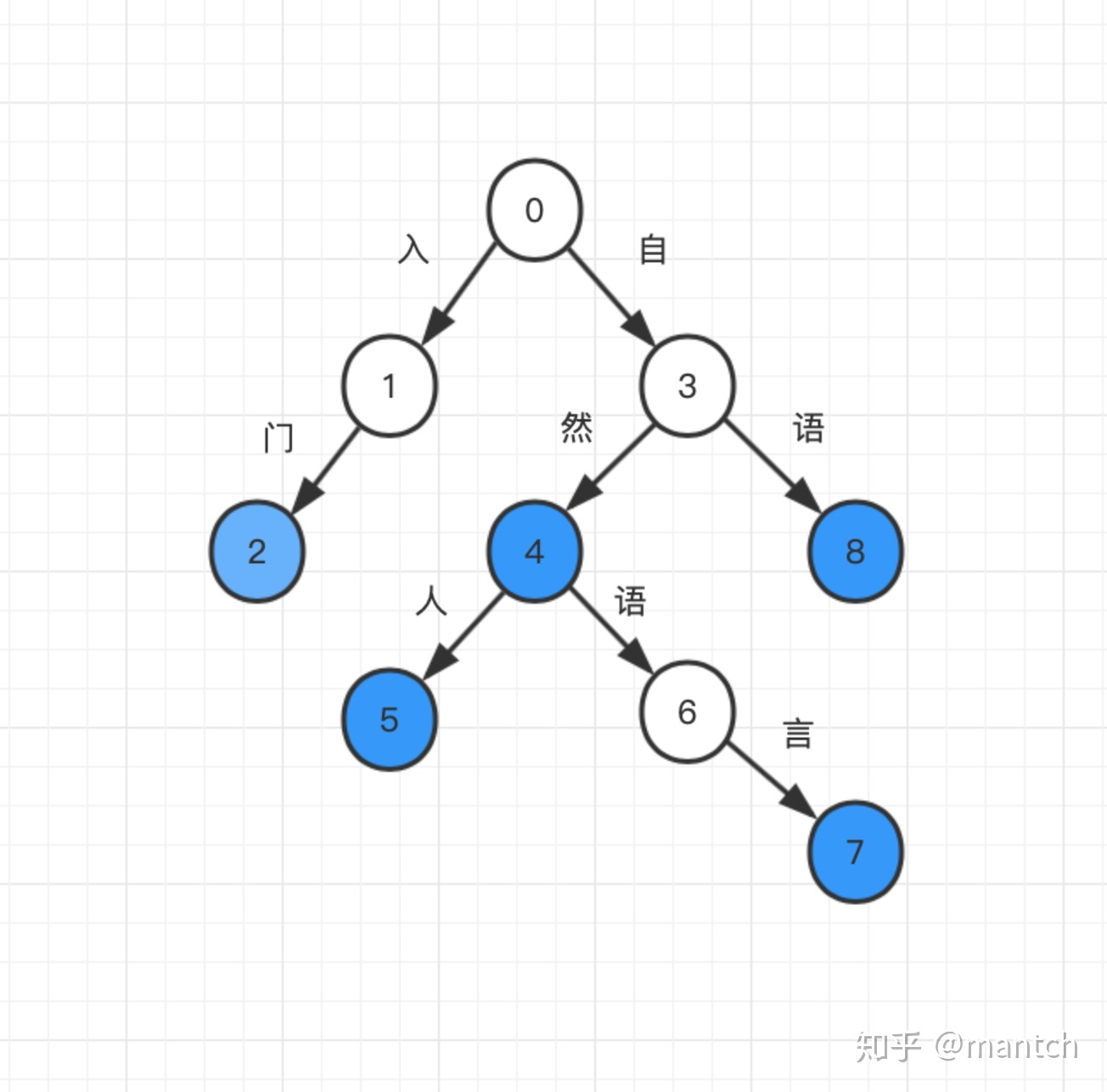
字典树也可以实现映射,只需将相应的值悬挂在键的终点节点上即可。
字典树的增删查改
首字散列其余二分的字典树
双数组字典树
双数组字典树是一种状态转移复杂度为常数的数据结构。
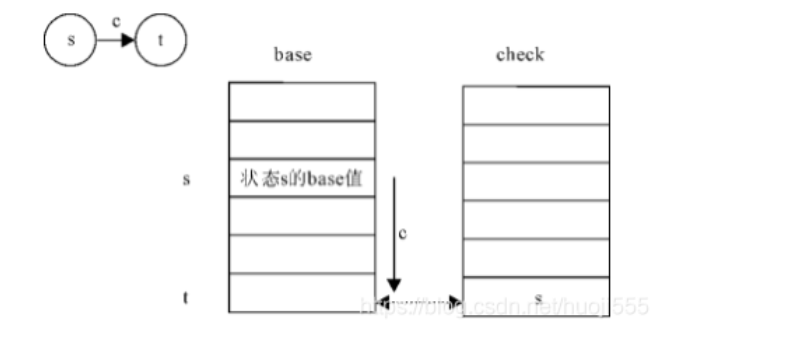
由base和check两个数组构成(base和check的索引表示一个状态),缩短状态转移过程的时间。
具体的,当状态b接受字符c转移到状态p时,满足条件(状态由整数下标表示):
state[p] = base[state[b]] + index[c]
check[state[p]] == state[b]
若条件不满足则转换失败。
如:当前状态自然(例如state[自然]=1),若想判断是否可以转移到状态自然人,先执行state[自然人] = base[state[自然]] + index[人] = base[1] + index[人],然后判断check[state[自然人]] == state[自然]是否成立即可,仅需一次加法和整数比较就能进行状态转移,转移过程为常数事件。
参考手把手教学 | 双数组字典树 - 知乎 (zhihu.com)
AC自动机
在使用字典树进行全切分时,每次都需要不断挪动起点,发起新的查询,这会显著增加时间复杂度,为了实现一次扫描就查询出所有出现过的单词,发明了AC自动机,它是常用的多模式匹配算法。
AC自动机使用前缀树来存放所有模式串的前缀,通过失配指针来处理失配的跳转。AC自动机的构建,首先需要构建Trie树,其次需要添加失配指针(fail表),最后需要模式匹配。下图是用单词her、say、she、shr、he构成的AC自动机。
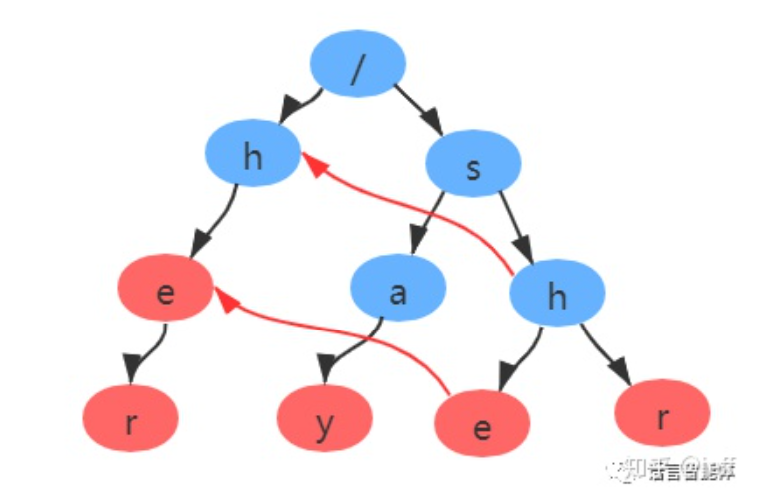
参考地铁十分钟 | AC自动机 - 知乎 (zhihu.com)
goto表
就是一棵前缀树,用来将每个模式串索引到前缀树上
output表
给定一个状态,我们需要知道该状态是否对应某个或某些字符串, 以决定是否输出模式串以及对应的值
fail表
存储的应该是fail指针,用来存储状态转移失败后应当回退的最佳状态,最佳状态指的是能记住已匹配上的字符串的最长后缀的那个状态。
基于双数组字典树的AC自动机
准确度评测
混淆矩阵
精确率
召回率
F1值