Word2vec
如果只看方法本身,word2vec 其实不复杂。它最核心的内容只有两种训练方式:
- CBOW
- Skip-gram
任务目标是生成一个嵌入词表,每一个词对应词表中的一行嵌入向量。
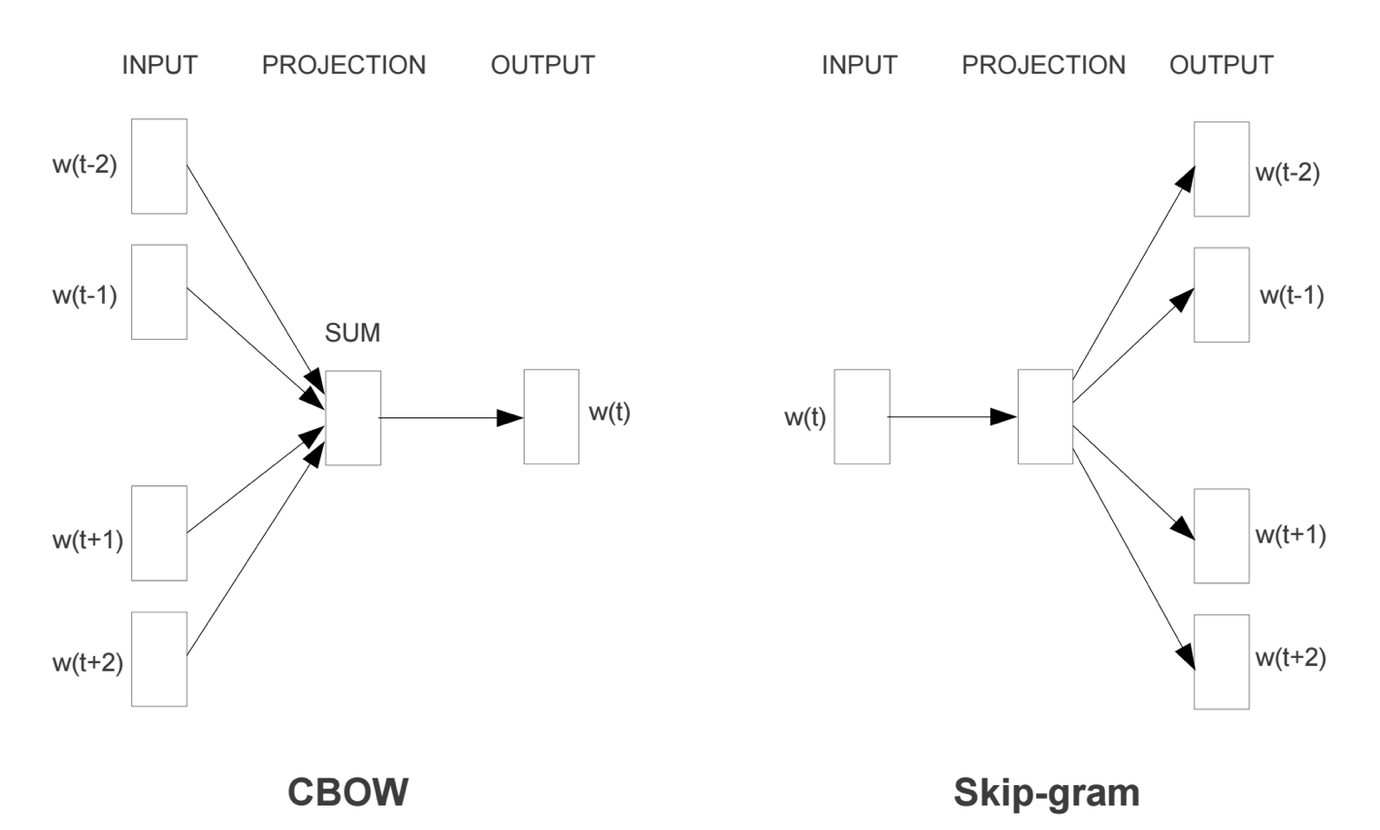
CBOW:用上下文预测中心词
CBOW 的全称是 Continuous Bag of Words。
它的训练目标是:
- 已知上下文词
- 预测中间的中心词
1. 一个具体样本怎么构造
还是用句子:
I like deep learning models
如果窗口大小取 2,并把 deep 当作中心词,那么一个训练样本可以写成:
- 输入:
I,like,learning,models - 输出:
deep
也就是说,CBOW 是把上下文聚合起来,去预测被遮住的中心词。
2. 训练流程
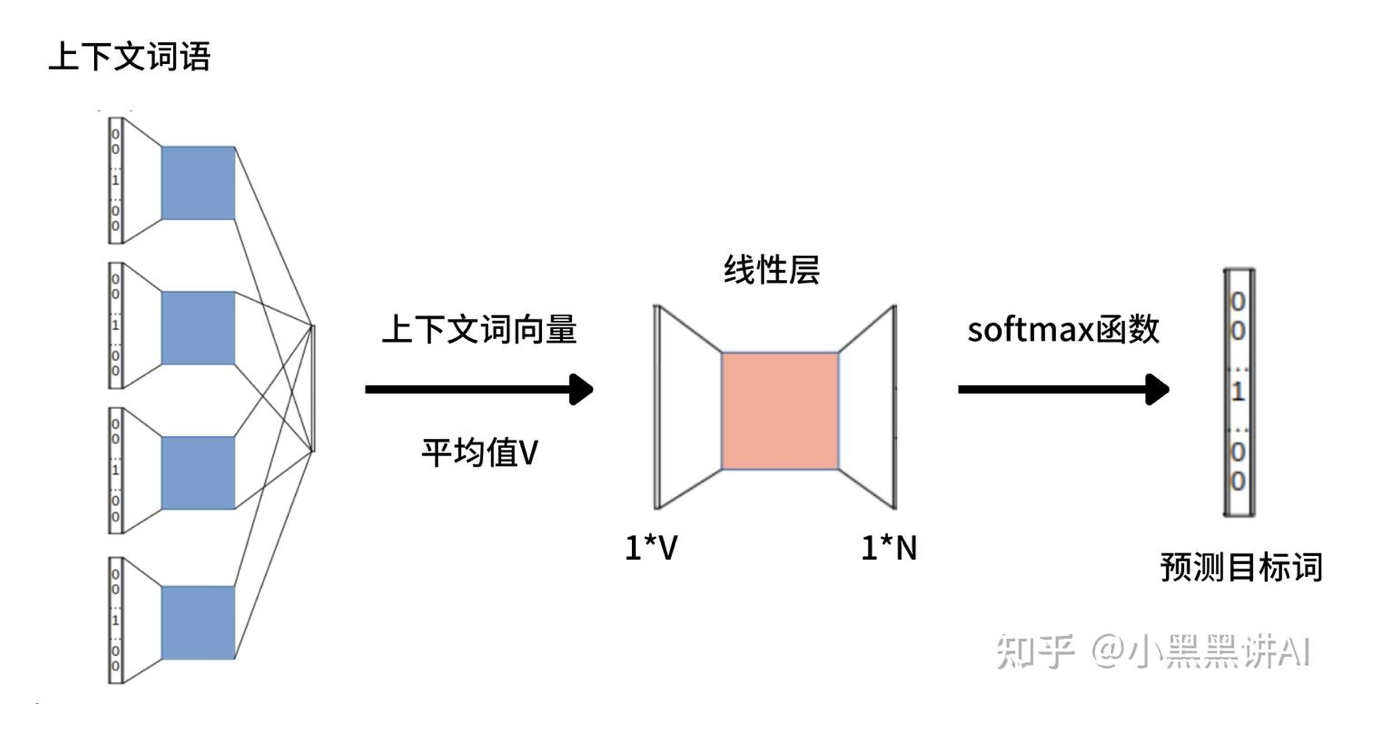
CBOW 的训练流程可以概括成四步:
- 把上下文词都表示成 one-hot
- 通过 embedding 矩阵查出它们对应的向量
- 对这些上下文向量做平均或求和
- 用这个聚合向量去预测中心词
假设词表大小是 V,embedding 维度是 d,embedding 矩阵记为:
$$
W \in \mathbb{R}^{V \times d}
$$
对于上下文词 w1, w2, ..., wk,先查出各自的词向量:
v1, v2, ..., vk
然后把它们聚合成一个上下文表示:
$$
h = \frac{v_1 + v_2 + \cdots + v_k}{k}
$$
再用这个 h 去预测中心词 wc 的概率分布:
$$
P(w_c \mid \text{context})
$$
如果采用 softmax,那么训练目标可以写成最小化负对数似然:
$$
L = -\log P(w_c \mid \text{context})
$$
3. 直观理解
CBOW 可以理解成一种“完形填空”:
- 给你周围几个词
- 让你猜中间最可能是什么词
如果模型经常看到:
I like _ learning models
它就会逐渐学到:
- 在这种上下文里,
deep出现的概率应该比较高
于是 deep 的词向量就会被训练成更适合这个上下文的位置。
4. CBOW 的特点
CBOW 的特点是:
- 训练速度通常更快
- 对高频词更稳定
- 因为把多个上下文词做平均,所以目标比较平滑
它更像是:
- 用上下文的整体语义去猜中心词
Skip-gram:用中心词预测上下文
Skip-gram 和 CBOW 的方向正好相反。
它的训练目标是:
- 已知中心词
- 预测它周围的上下文词
1. 一个具体样本怎么构造
还是句子:
I like deep learning models
如果把 deep 当作中心词,窗口大小还是 2,那么它会被拆成多个训练对子:
- (
deep->I) - (
deep->like) - (
deep->learning) - (
deep->models)
也就是说:
- CBOW 是“多个上下文 -> 一个中心词”
- Skip-gram 是“一个中心词 -> 多个上下文词”
2. 训练流程
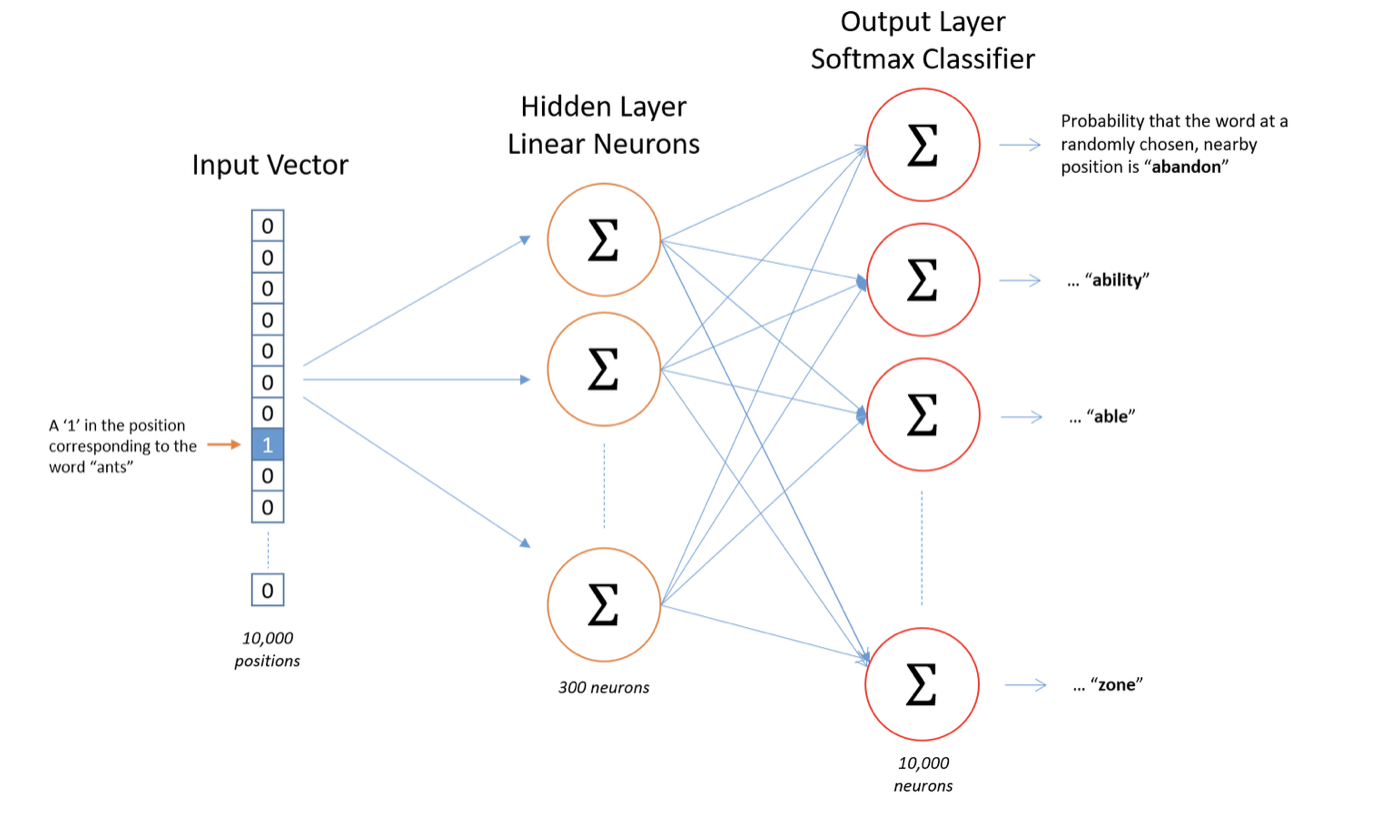
Skip-gram 的训练过程也可以概括成四步:
- 输入中心词的 one-hot
- 从 embedding 矩阵中取出中心词向量
- 用这个向量分别去预测窗口中的每个上下文词
- 对多个上下文词的损失求和
假设中心词是 wi,它对应的输入向量记为 vi。
对于一个目标上下文词 wo,模型要最大化:
$$
P(w_o \mid w_i)
$$
如果使用 softmax,这个概率写成:
$$
P(w_o \mid w_i) = \frac{\exp(v_o^T v_i)}{\sum_{w=1}^{V} \exp(v_w^T v_i)}
$$
其中:
vi是中心词的输入向量vo是目标上下文词的输出向量
这个公式的意思其实很简单:
- 如果中心词和上下文词真的经常一起出现
- 那么它们的向量点积就应该更大
- 点积越大,被 softmax 分到的概率就越高
如果窗口内的上下文词集合记为 C(wi),那么 Skip-gram 的训练目标可以写成:
$$
L = - \sum_{w_o \in C(w_i)} \log P(w_o \mid w_i)
$$
3. 直观理解
Skip-gram 可以理解成一种“扩散预测”:
- 给你一个词
- 让你去猜它周围最可能出现哪些词
例如给定 deep,模型会学习:
- 它附近更可能出现
learning - 也可能出现
models - 不太可能出现完全无关的词
这样训练多了之后,词向量就会逐渐把共现关系编码进去。
4. Skip-gram 的特点
Skip-gram 的特点是:
- 对低频词往往更友好
- 更容易学到细粒度的共现关系
- 一个中心词会拆成多个训练样本,因此训练信号更细
所以在很多语料上,Skip-gram 学出的词向量会更有表现力。
负采样:用更便宜的损失替代完整 softmax
原始 Skip-gram 的 softmax 最大问题是:
- 分母要对整个词表求和
词表一大,训练代价就非常高。
负采样的做法是把问题改写成二分类任务。对于一个真实共现的词对 (wi, wo),把它当成正样本;再随机采样 K 个负样本 w1^- , ..., wK^-。
这时单个样本的损失函数可以写成:
$$
L = -\log \sigma(v_o^T v_i) - \sum_{j=1}^{K} \log \sigma\left(-{v_j^-}^T v_i\right)
$$
其中:
σ是 sigmoid 函数vi是中心词向量vo是正样本上下文词向量v_j^-是第j个负样本词向量
这个损失的含义很直接:
- 对正样本,希望
vo^T vi越大越好 - 对负样本,希望
v_j^- ^T vi越小越好
也就是说,训练目标就是:
- 把真实共现的词拉近
- 把随机采样的无关词推远
这样一来,每次更新只需要处理:
- 1 个正样本
K个负样本
而不需要遍历整个词表,所以训练会快很多。
实际中大家常说的:
- Skip-gram with Negative Sampling
本质上就是:
Skip-gram 定义预测任务
Negative Sampling 定义高效可训练的损失函数
(
deep,learning)
当作正样本。
同时再随机采一些负样本,比如:
- (
deep,banana) - (
deep,railway) - (
deep,window)
训练时模型会被推动去学习:
deep和learning的点积应该更大deep和banana、railway、window的点积应该更小
这样训练多了以后,“经常共现的词彼此更接近”这个结构就会在 embedding 空间中逐渐形成。
Item2vec
其实就是Word2vec在Item上的实现,可以用于构建物品塔
词语 → 物品
句子 → 用户交互序列
词语共现 → 物品共同被用户交互
Item2vec和Word2vec唯一的不同在于,Item2vec摒弃了时间的概念,认为序列中任意两个物品都相关。
Graph Embedding
DeepWalk
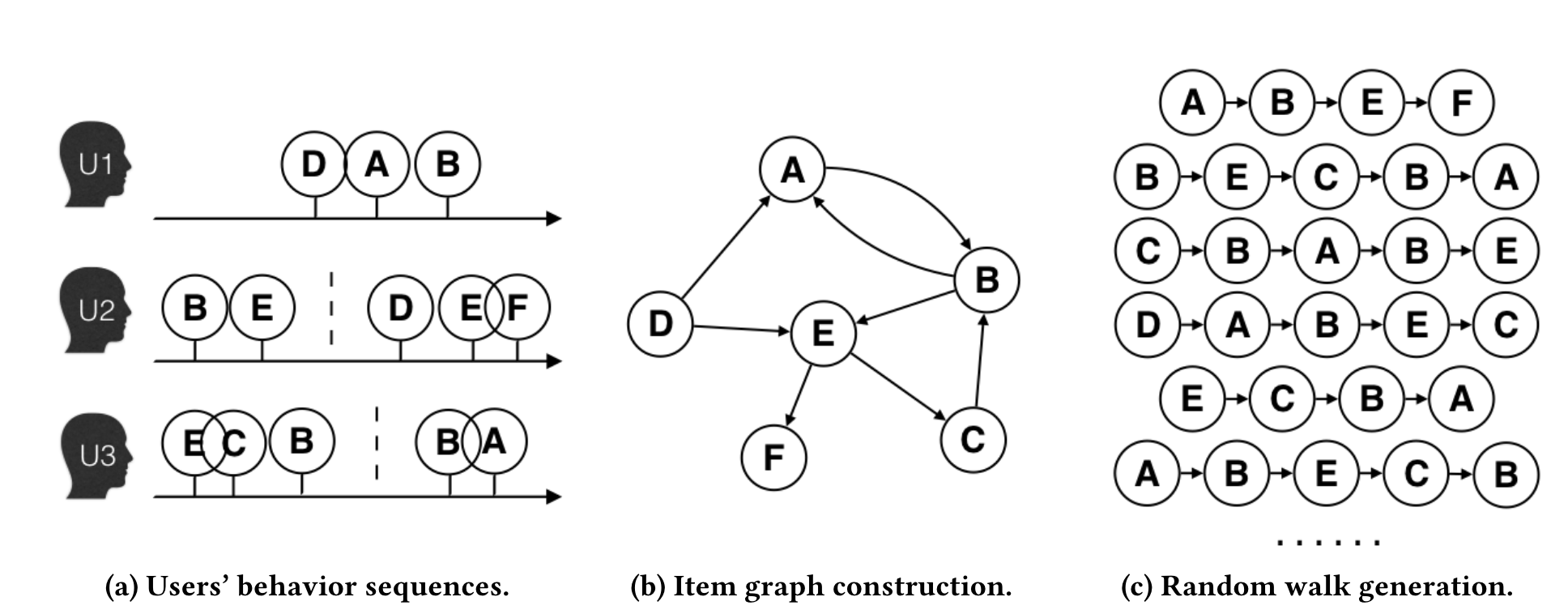
图(a)是原始的用户行为序列。
图(b)基于这些用户行为序列构建了物品关系图。可以看出,物品A和B之间的边产生的原因是用户U1先后购买了物品A和物品B。如果后续产生了多条相同的有向边,则有向边的权重被加强。在 将所有用户行为序列都转换成物品关系图中的边之后,全局的物品关系图就建立起来了。
图(c)采用随机游走的方式随机选择起始点,重新产生物品序列。
最后将这些物品序列输入Word2vec 模型中, 生成最终的物品Embedding向量。
Node2vec
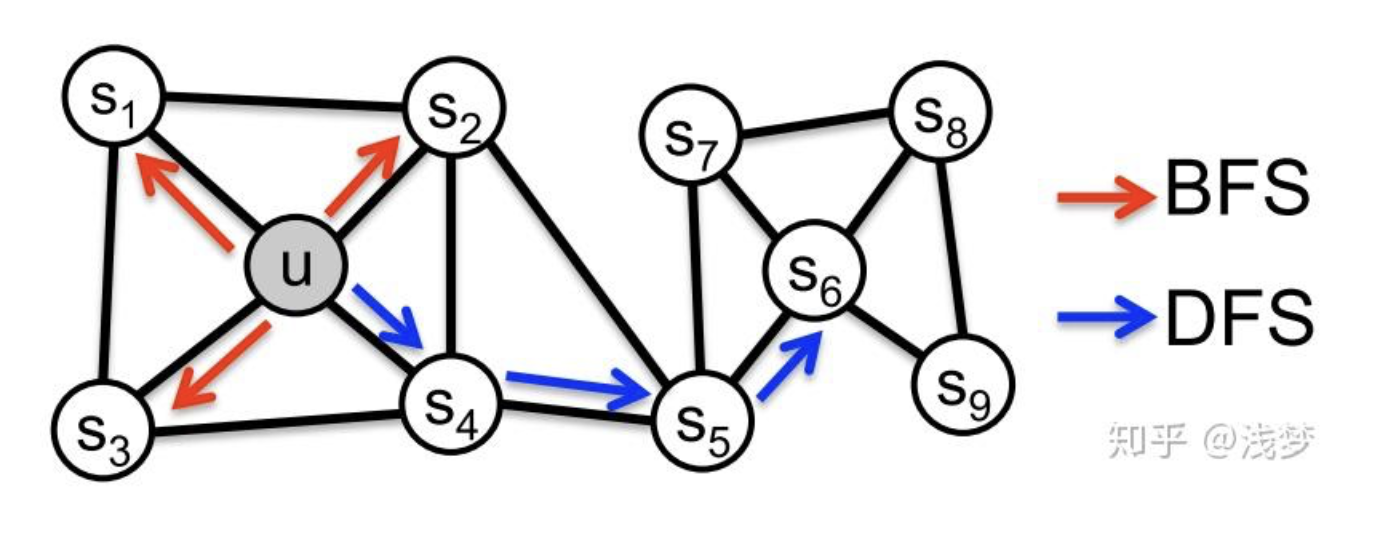
DeepWalk 的核心做法是:
- 在图上做随机游走
- 把游走得到的节点序列当作“句子”
- 再用 Word2vec 学节点向量
Node2vec 可以看作是 DeepWalk 的增强版。它最关键的改进在于:
- 它不是做完全均匀的随机游走
- 而是通过两个参数控制游走更偏向 BFS 还是 DFS
也就是说,Node2vec 的重点不只是“在图上走”,而是:
- 如何走,决定了最终 embedding 更偏向学习哪类图结构信息
1. 为什么要引入有偏随机游走
在图结构中,我们往往希望 embedding 能表达两类信息:
- 局部邻居关系
- 结构角色关系
例如在推荐系统里:
- 如果两个商品经常和同一批商品一起出现,它们可能属于同一兴趣簇
- 如果两个商品虽然不直接相邻,但在图中扮演类似的桥接角色,它们也可能结构相似
DeepWalk 的随机游走比较平均,无法显式控制更强调哪一类关系。Node2vec 则通过有偏采样补上了这一点。
2. p 和 q 两个参数
设随机游走中前一个节点是 t,当前节点是 v,下一步候选节点是 x。
Node2vec 通过两个超参数控制转移概率:
p:return parameterq:in-out parameter
更具体地说,在当前节点 v 上,从上一个节点 t 出发,走向候选节点 x 的未归一化转移概率可以写成:
$$
\pi_{vx} = \alpha_{pq}(t, x)\cdot w_{vx}
$$
其中:
- $w_{vx}$ 表示边 $(v,x)$ 的权重
- $\alpha_{pq}(t, x)$ 是由
p和q控制的偏置项
偏置项定义为:
$$
\alpha_{pq}(t, x)=\frac{1}{p}\ \text{if } d_{tx}=0,\quad
\alpha_{pq}(t, x)=1\ \text{if } d_{tx}=1,\quad
\alpha_{pq}(t, x)=\frac{1}{q}\ \text{if } d_{tx}=2
$$
这里 $d_{tx}$ 表示节点 $t$ 和节点 $x$ 之间的最短路径距离。
这个公式的含义是:
- 如果
x = t,也就是走回上一个节点,那么转移权重是 $\frac{1}{p}$ - 如果
x是当前节点v的邻居,且和t也相邻,那么权重是 $1$ - 如果
x更远一些,那么权重是 $\frac{1}{q}$
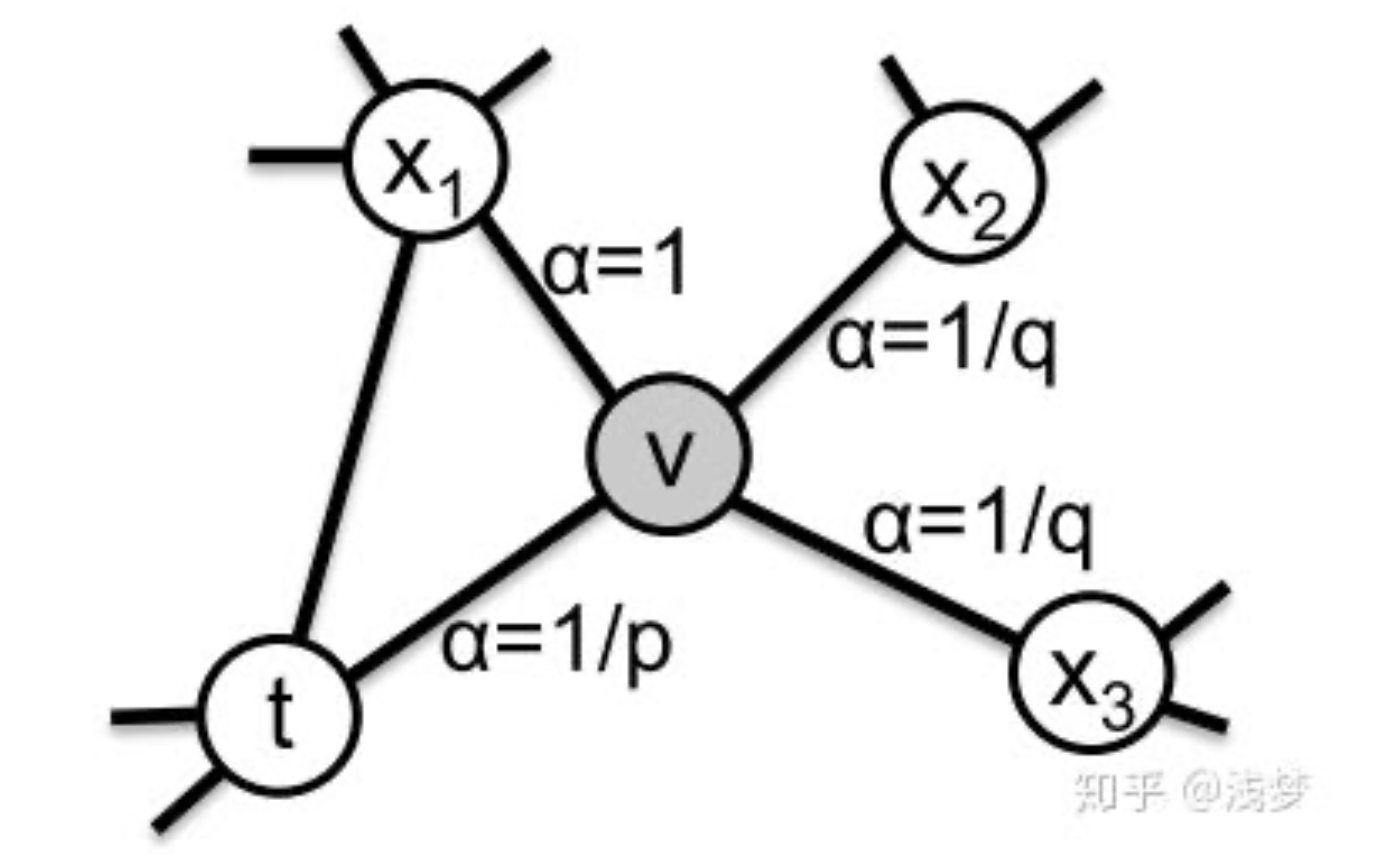
它们的直观作用可以这样理解。
p 控制是否容易“走回头路”:
p大,回到上一个节点的概率更低p小,更容易回到刚访问过的节点
q 控制游走更像 BFS 还是 DFS:
q大,更倾向停留在当前节点附近,更像 BFSq小,更倾向往远处探索,更像 DFS
所以:
- BFS 风格更容易捕捉同一局部社区中的相似节点
- DFS 风格更容易捕捉结构角色相似的节点
EGES
EGES 全称是 Enhanced Graph Embedding with Side Information,是推荐系统场景下很有代表性的一种图 embedding 方法。
它要解决的问题非常实际:
- 如果只靠图结构来学 item embedding,热门商品通常能学得很好
- 但冷启动商品或者交互很少的商品,向量往往不稳定
因为在推荐系统里,商品不只有行为数据,还通常有很多 side information,例如:
- 类目
- 品牌
- 店铺
- 标题关键词
这些信息即使在行为很少时,也能提供很强的先验。
1. EGES 的核心思想
EGES 的核心思想可以概括成一句话:
- item 的表示不应该只来自图结构,还应该融合它本身的属性信息
所以它的流程通常可以理解为:
- 根据用户行为构建 item 图
- 在图上做随机游走,生成 item 序列
- 在训练 embedding 时,把 item ID 和 side information 一起编码
前两步和 DeepWalk / Node2vec 很像,真正的区别出现在第三步。
2. 为什么 side information 很重要
如果只用 item ID 学 embedding,那么只有交互充分的商品才能学到比较稳定的向量。
而对于冷启动商品:
- 行为序列短
- 图中连接少
- 采样得到的上下文不充分
这时单靠图结构往往不够。
但如果我们知道这个商品还属于:
- 某个类目
- 某个品牌
- 某个店铺
那么这些属性就可以帮助模型在数据不足时仍然学到更合理的表示。
3. EGES 怎么融合 side information
EGES 的做法不是简单平均所有 side information,而是:
- 为 item ID 和每一种 side information 都学习一个 embedding
- 再学习一组权重,决定不同信息源的重要性
也就是说,一个商品最终的表示不只是:
e_item
而更像是:
e = α0 e_item + α1 e_category + α2 e_brand + ...
其中这些权重 α 不是手工指定的,而是通过训练学出来的。
这个设计很关键,因为不同商品对 side information 的依赖程度并不一样。
例如:
- 有些商品行为很多,item ID 本身就足够
- 有些商品很新,这时类目、品牌等 side information 会更重要
EGES 通过学习权重,让模型自动决定该更依赖哪一类信息。
4. 和 DeepWalk / Node2vec 的区别
可以简单这样理解:
- DeepWalk:只利用图结构
- Node2vec:利用图结构,并改进随机游走策略
- EGES:在图结构基础上,进一步融合 side information
所以 EGES 的意义不在于完全推翻前面的图 embedding 方法,而在于:
- 把更符合推荐系统实际的数据条件融了进来
5. 在推荐场景中的价值
EGES 特别适合:
- 电商推荐
- 内容推荐
- 冷启动比较明显的 item 场景
因为在这些场景里,单靠用户行为往往是不够的。
它抓住了推荐系统里一个非常真实的问题:
- 商品不只有“在图中的位置”
- 还有“它本身的属性信息”
而一个更好的 embedding,通常应该同时利用这两部分信息。