MIND
Li C, Liu Z, Wu M, et al. Multi-interest network with dynamic routing for recommendation at Tmall[C]//Proceedings of the 28th ACM international conference on information and knowledge management. 2019: 2615-2623.
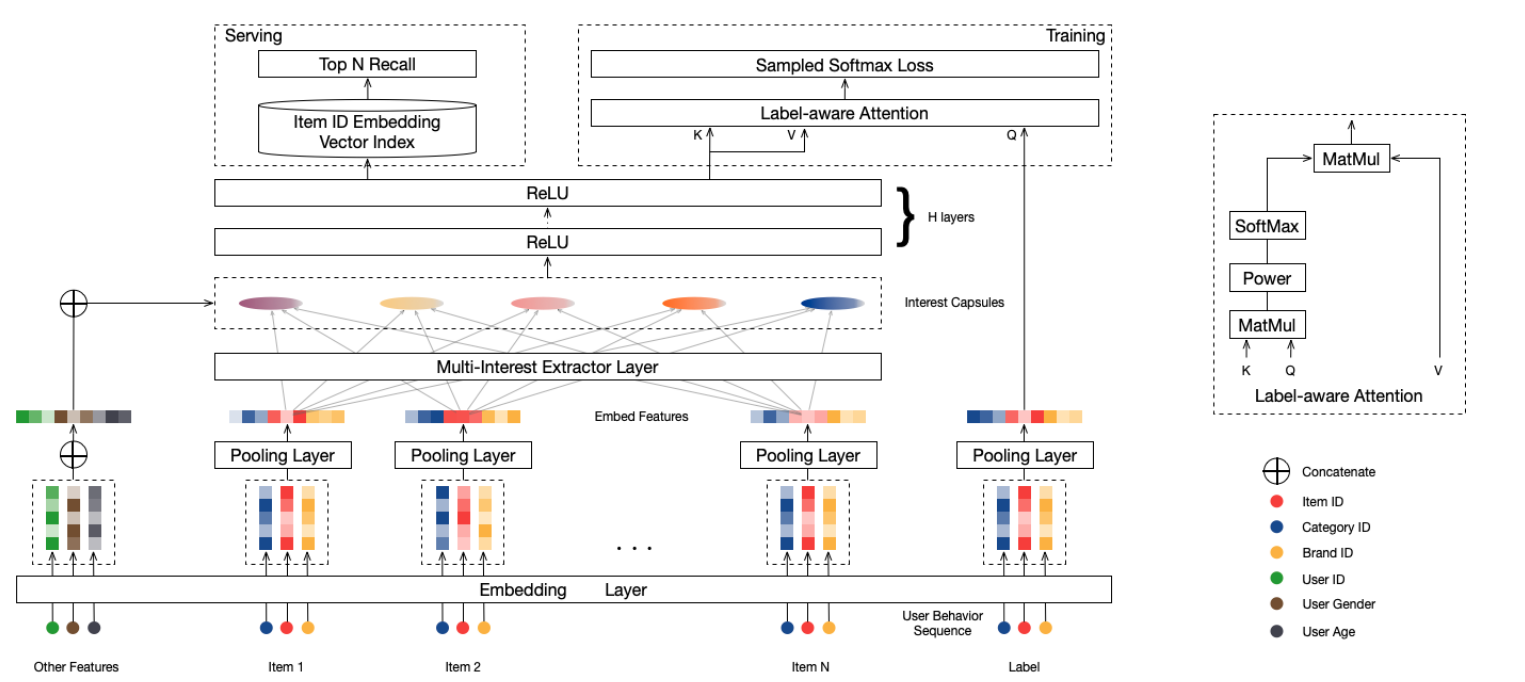
传统召回模型通常把用户压成一个向量,但单向量很难表达用户的多兴趣结构。MIND 的核心做法是:把用户历史行为映射成多个兴趣向量,再让目标 item 选择最相关的那个兴趣参与训练。
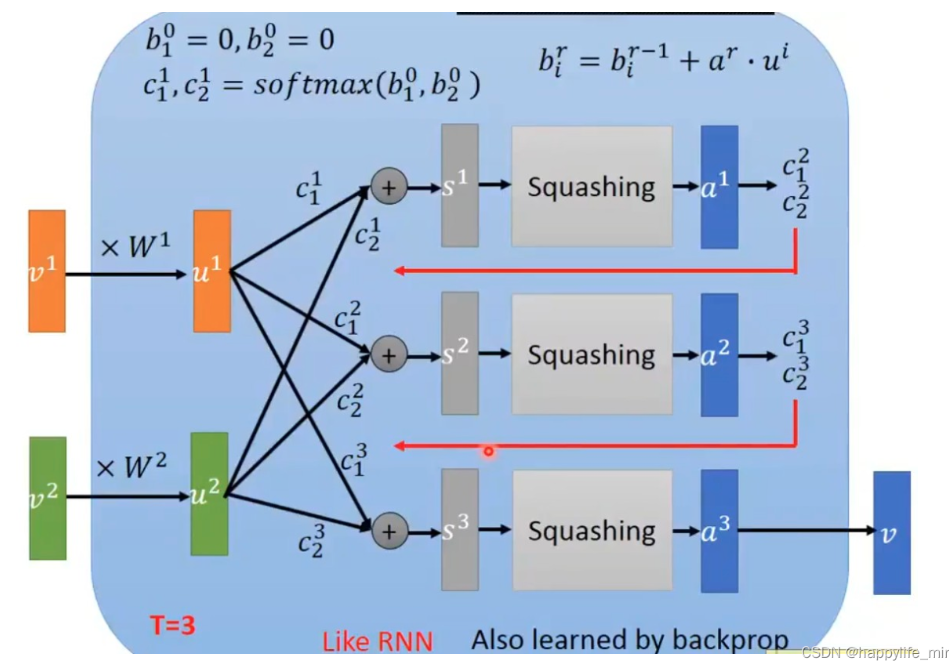
胶囊网络介绍
MIND 借鉴了胶囊网络里的动态路由思想。这里可以把:
- 用户历史行为向量看成低层 capsule
- 用户兴趣向量看成高层 capsule
动态路由的目标不是简单 pooling,而是把行为向量自适应地分配到不同兴趣上。

多兴趣提取层
设用户行为序列对应的 item embedding 为:
$$
E = {e_1, e_2, \ldots, e_n}
$$
MIND 希望从中提取出 $K$ 个兴趣向量:
$$
V = {v_1, v_2, \ldots, v_K}
$$
其中 $v_j \in \mathbb{R}^d$ 表示第 $j$ 个兴趣 capsule。
先把行为向量做线性映射:
$$
\hat{e}_{ij} = W_j e_i
$$
其中 $W_j$ 是第 $j$ 个兴趣 capsule 对应的变换矩阵。
然后通过 routing logit $b_{ij}$ 计算行为 $i$ 分配给兴趣 $j$ 的权重:
$$
c_{ij} = \frac{\exp(b_{ij})}{\sum_{k=1}^{K}\exp(b_{ik})}
$$
接着聚合得到第 $j$ 个兴趣 capsule 的输入:
$$
s_j = \sum_{i=1}^{n} c_{ij}\hat{e}_{ij}
$$
再经过 squash 函数得到兴趣向量:
$$
v_j = \mathrm{squash}(s_j)
= \frac{|s_j|^2}{1+|s_j|^2}\frac{s_j}{|s_j|}
$$
最后根据 agreement 更新 routing logit:
$$
b_{ij} \leftarrow b_{ij} + \hat{e}_{ij}^{\top} v_j
$$
重复若干轮后,相似行为会被分到同一个兴趣 capsule 中。
Label-Aware 注意力层
设目标 item embedding 为 $e_t$。MIND 用目标 item 和多个兴趣向量计算注意力权重,从而选出和当前目标最相关的兴趣。
先计算相似度分数:
$$
g_j = v_j^{\top} e_t
$$
再通过幂指数放大差异:
$$
a_j = \frac{\exp(g_j^p)}{\sum_{k=1}^{K}\exp(g_k^p)}
$$
其中 $p$ 是可调超参数。$p$ 越大,注意力越接近 hard attention。
最后得到与目标 item 对齐的用户表示:
$$
u = \sum_{j=1}^{K} a_j v_j
$$
这一步的作用是:训练时不再让一个目标 item 同时对齐所有兴趣,而是重点更新最相关的那个兴趣表示。
训练流程
训练时,先用动态路由得到多个兴趣向量,再用目标 item 通过 Label-Aware Attention 得到用户表示 $u$。随后计算用户和目标 item 的匹配分数:
$$
z = u^{\top} e_t
$$
如果采用 sampled softmax,训练目标可以写成:
$$
P(i_t \mid u) = \frac{\exp(u^{\top} e_t)}{\sum_{i \in \mathcal{I}}\exp(u^{\top} e_i)}
$$
$$
\mathcal{L} = - \log P(i_t \mid u)
$$
在线召回时,用户最终不再对应一个向量,而是对应多个兴趣向量 $v_1, \ldots, v_K$。可以让每个兴趣向量分别去检索候选 item,再把结果合并。这样比单向量用户表示更容易覆盖用户的多样化兴趣。
SDM
Lv F, Jin T, Yu C, et al. SDM: Sequential deep matching model for online large-scale recommender system[C]//Proceedings of the 28th ACM international conference on information and knowledge management. 2019: 2635-2643.
MIND解决了兴趣“广度”的问题,但新的问题随之而来:时间。 用户兴趣不仅是多元的,还是动态演化的。一个用户在一次购物会话中的行为,往往比他一个月前的行为更能预示他下一刻的需求。MIND虽然能捕捉多个兴趣,但并未在结构上显式地区分它们的时效性。序列深度匹配模型(SDM) 正是为了解决这一问题而提出的。SDM模型的核心思想是分别建模用户的短期即时兴趣和长期稳定偏好,然后智能地融合它们。
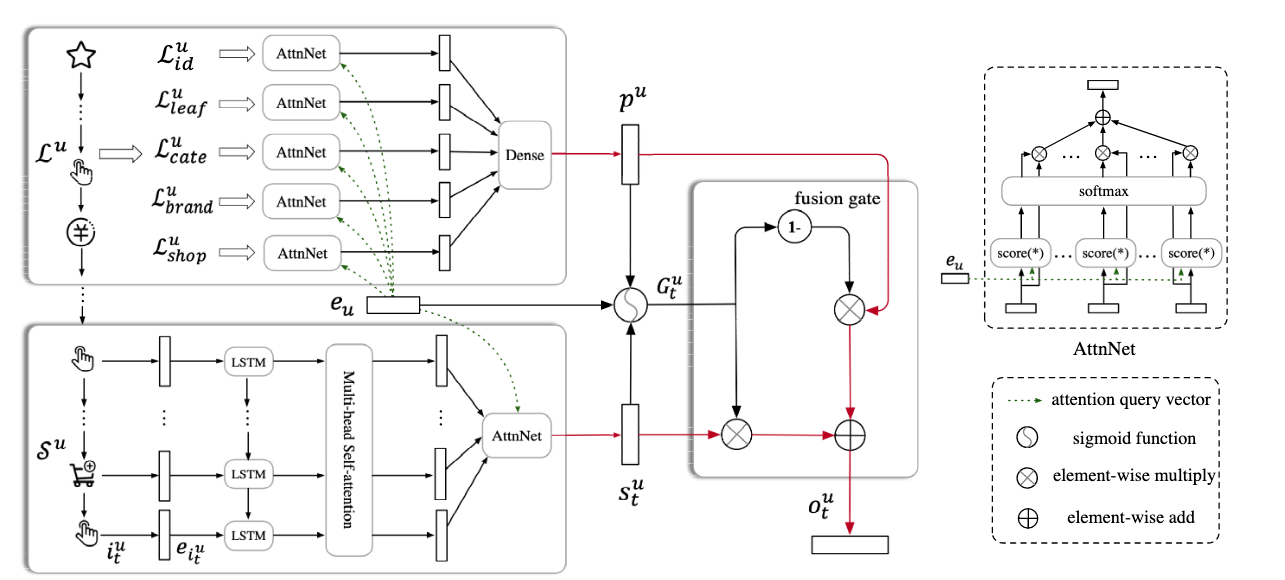
捕捉短期兴趣
SDM 用用户最近的一段行为序列来建模短期兴趣。根据图中的结构,短期路径由 LSTM + Multi-head Self-Attention + AttnNet 组成。设最近 $T$ 个行为对应的 item embedding 为:
$$
S = {e_1, e_2, \ldots, e_T}
$$
先用 LSTM 编码顺序信息,第 $t$ 步隐状态为:
$$
h_t = \mathrm{LSTM}(e_t, h_{t-1})
$$
然后用多头自注意力进一步建模行为之间的依赖关系。若记
$$
H = [h_1, h_2, \ldots, h_T]
$$
则自注意力输出可以写成:
$$
\tilde{H} = \mathrm{MultiHead}(H, H, H)
$$
其中 $\tilde{H} = [\tilde{h}_1, \tilde{h}_2, \ldots, \tilde{h}_T]$。
接下来,图中的 AttnNet 会使用查询向量 $e_u$ 对这些时序表示做注意力汇聚。其打分形式可以写成:
$$
r_t = \mathrm{score}(\tilde{h}_t, e_u)
$$
$$
\alpha_t = \frac{\exp(r_t)}{\sum_{j=1}^{T}\exp(r_j)}
$$
最终得到短期兴趣表示:
$$
s_t^u = \sum_{t=1}^{T}\alpha_t \tilde{h}_t
$$
其中 $e_u$ 可以理解为当前匹配任务对应的查询向量,AttnNet 会让和当前目标更相关的近期行为获得更大的权重。
捕捉长期兴趣
短期兴趣描述“此刻想买什么”,长期兴趣描述“这个人稳定偏好什么”。从图里可以看到,SDM 的长期兴趣并不是直接从长序列中提,而是从多路用户画像特征中提取,包括:
- user id
- leaf
- cate
- brand
- shop
记这些特征集合分别为 L_id^u、L_leaf^u、L_cate^u、L_brand^u 和 L_shop^u。
每一路特征都会经过一个 AttnNet,并共享查询向量 $e_u$。以第 $m$ 路特征集合 $L_m^u = {x_1^m, x_2^m, \ldots, x_{N_m}^m}$ 为例,其注意力权重为:
$$
\beta_i^m = \frac{\exp(\mathrm{score}(x_i^m, e_u))}{\sum_{j=1}^{N_m}\exp(\mathrm{score}(x_j^m, e_u))}
$$
对应的第 $m$ 路长期偏好表示为:
$$
p_m^u = \sum_{i=1}^{N_m} \beta_i^m x_i^m
$$
最后把多路画像表示拼接后经过一层全连接,得到长期兴趣表示:
$$
p^u = \phi\left(W_p [p_{id}^u; p_{leaf}^u; p_{cate}^u; p_{brand}^u; p_{shop}^u] + b_p\right)
$$
其中 $\phi(\cdot)$ 表示图中的 Dense 层变换。
长短期兴趣融合
有了短期兴趣 $s_t^u$ 和长期兴趣 $p^u$ 之后,SDM 使用 fusion gate 做自适应融合,而不是固定加权。
从图里可以看出,门控值 $G_t^u$ 同时依赖:
- 长期兴趣 $p^u$
- 短期兴趣 $s_t^u$
- 查询向量 $e_u$
因此可以写成:
$$
G_t^u = \sigma\left(W_g [p^u; s_t^u; e_u] + b_g\right)
$$
其中 $G_t^u \in (0,1)^d$ 表示逐维门控权重。根据图中的 1-、逐元素乘法和逐元素加法,最终输出表示为:
$$
o_t^u = G_t^u \odot s_t^u + (1 - G_t^u) \odot p^u
$$
其中 $\odot$ 表示逐元素乘法。
得到最终用户表示 $o_t^u$ 后,就可以和目标 item 做匹配。若目标 item 向量记作 $v_i$,则打分函数可以写成:
$$
z_i = {o_t^u}^{\top} v_i
$$
如果采用 softmax 形式训练,则目标概率为:
$$
P(i_t \mid o_t^u) = \frac{\exp({o_t^u}^{\top} v_{i_t})}{\sum_{i \in \mathcal{I}} \exp({o_t^u}^{\top} v_i)}
$$
对应损失函数为:
$$
\mathcal{L} = -\log P(i_t \mid o_t^u)
$$
所以 SDM 的核心可以概括成:
- 短期路径刻画最近行为的时序依赖
- 长期路径从多路画像特征中提取稳定偏好
- fusion gate 根据当前查询向量动态平衡短期和长期兴趣