DIN
在推荐系统里,用户兴趣并不是一个固定不变的向量,而是会随着候选物品的不同而表现出不同侧面。
例如同一个用户既买过母婴用品,也看过数码产品。当我们要预测他是否会点击一款婴儿车时,历史里的母婴行为显然更重要;而在预测他是否会购买耳机时,数码相关行为又更有参考价值。
传统的 Embedding + MLP 排序模型,通常会把用户历史行为池化成一个固定长度向量,例如平均池化或求和池化:
$$
v_u = \frac{1}{T}\sum_{i=1}^{T} e_i
$$
其中:
- $e_i$ 表示第 $i$ 个历史行为 item 的 embedding
- $T$ 表示行为序列长度
- $v_u$ 表示汇总后的用户兴趣表示
这种做法虽然简单,但问题也很明显:
- 所有历史行为被一视同仁
- 用户兴趣被压缩成单一静态向量
- 无法根据当前候选广告或商品动态调整关注重点
DIN(Deep Interest Network)提出的核心思想就是:
- 不预先生成一个固定的用户兴趣向量
- 而是针对当前候选 item,自适应地从历史行为里挑选更相关的兴趣信号
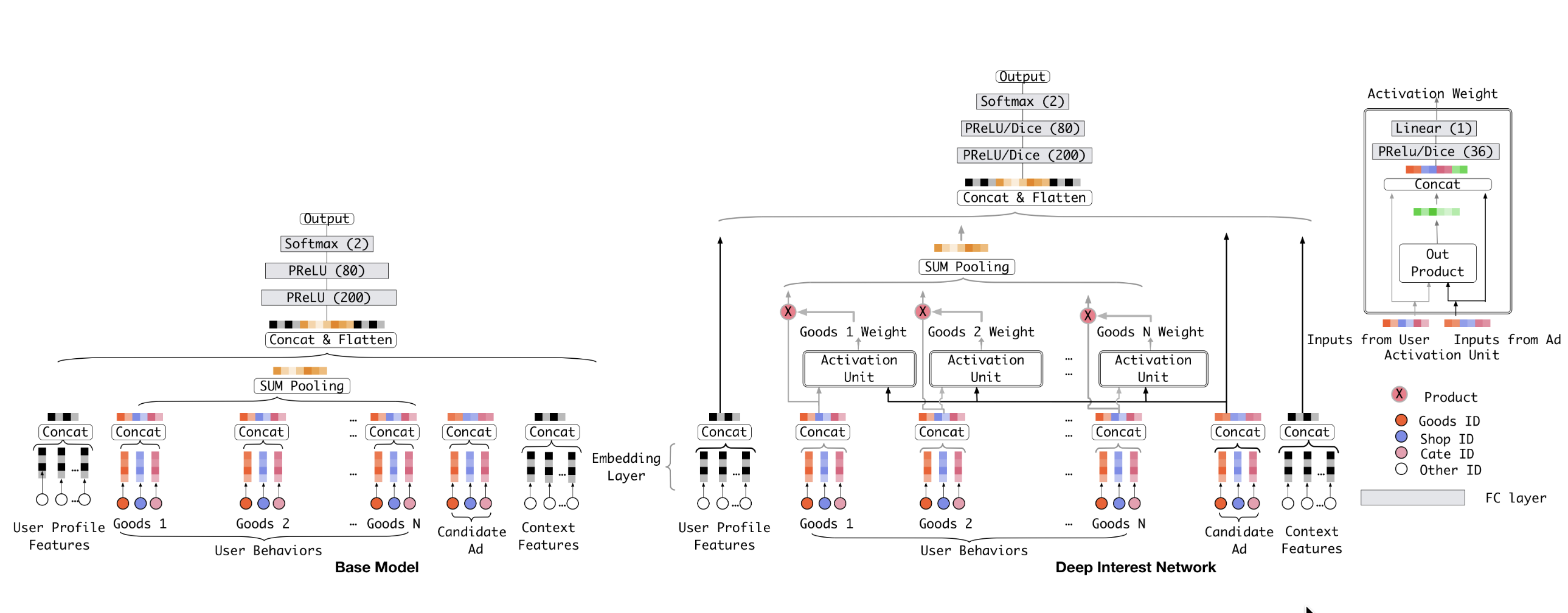
1. 核心动机
DIN 最重要的观察是:用户兴趣是局部激活的。
也就是说,用户并不是始终对所有兴趣都保持同样强度,而是在面对某个候选 item 时,只会激活与它相关的那部分历史兴趣。
因此,DIN 不再简单做平均池化,而是引入注意力机制,让候选 item 作为 query,历史行为作为 key/value,计算不同历史行为对当前目标的相关程度。
2. 兴趣激活单元
设当前候选 item 的 embedding 为 $e_a$,用户历史行为序列为:
$$
{e_1,e_2,\ldots,e_T}
$$
DIN 会先计算每个历史行为和候选 item 之间的匹配分数:
$$
w_i = f(e_i, e_a)
$$
这里的 $f(\cdot)$ 通常是一个前馈网络,输入可能包括:
- $e_i$
- $e_a$
- $e_i - e_a$
- $e_i \odot e_a$
其中 $\odot$ 表示逐元素乘积。
得到权重后,对历史行为做加权汇总:
$$
v_u(e_a) = \sum_{i=1}^{T} w_i e_i
$$
注意这里的 $v_u(e_a)$ 不再是一个固定的用户向量,而是和候选 item 相关的兴趣表示。
这就是 DIN 相比传统 pooling 的本质区别。
3. 模型结构
DIN 的整体流程可以理解为下面几步:
- 对用户画像、上下文特征、候选 item、历史行为序列分别做 embedding
- 用候选 item 对历史行为序列做 attention,生成与当前目标相关的兴趣表示
- 将兴趣表示与其他特征拼接
- 输入多层感知机(MLP)输出点击率或转化率
因此,从结构上看,DIN 仍然属于 CTR 预估中的深度排序模型,只不过它在“用户兴趣建模”这一层引入了目标感知的注意力机制。
4. DIN 解决了什么问题
DIN 相比早期的 Wide & Deep、DeepFM 一类模型,主要改进在于:
- 从静态兴趣建模转向动态兴趣激活
- 让历史行为不再等权参与预测
- 显式建模“候选 item 和历史行为是否相关”
对于电商场景尤其有效,因为用户的浏览、点击、加购、购买行为天然带有强烈的多兴趣特征。
5. 感知 mini-batch 的正则化
除了兴趣激活单元本身,DIN 论文里还提到了一个比较工程化、但很实用的训练技巧:mini-batch aware regularization。
CTR 模型里大量参数来自 embedding,尤其是用户、item、类目等高维稀疏特征。若直接对全部 embedding 参数做普通 $L_2$ 正则:
$$
\lambda \lVert \theta \rVert_2^2
$$
虽然形式上很简单,但在工业场景里会遇到一个问题:
- 参数规模极大
- 每个 mini-batch 实际只访问其中很小一部分 embedding
- 如果每一步都对全量参数做正则,计算和存储代价都很高
DIN 的做法是:只对当前 mini-batch 里真正出现过的稀疏特征参数施加正则约束。
直观理解就是:
- 这一批样本没有出现的 embedding,就不在这一轮额外计算正则
- 这一批样本访问到的 embedding,才参与当前 batch 的惩罚项
这样做的好处是:
- 更适合超大规模稀疏参数训练
- 降低无意义的全量正则计算开销
- 在工程上更容易和稀疏更新框架结合
6. 数据自适应激活函数
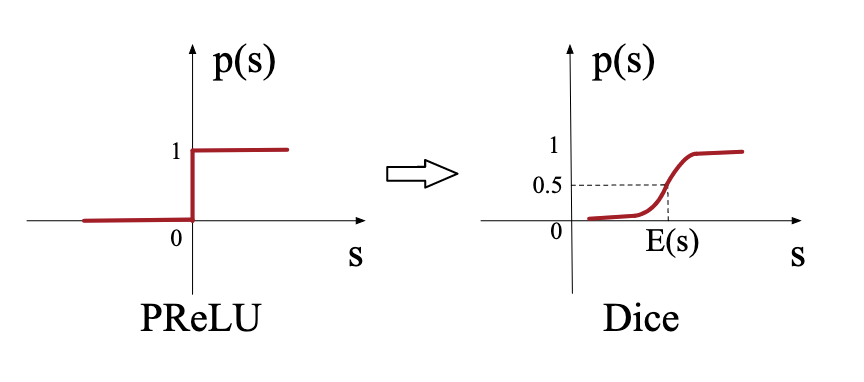
DIN 里另一个常被提到的技巧,是数据自适应激活函数 DICE(Data Adaptive Activation Function)。
在普通 MLP 里,常见激活函数是 ReLU:
$$
\mathrm{ReLU}(x) = \max(0, x)
$$
但 CTR 场景有一个特点:
- 不同层、不同特征维度的输入分布差异很大
- 同一层神经元在不同 batch 下的激活分布也可能不断变化
固定形状的激活函数,有时不能很好适应这种分布漂移。
DICE 的核心思想是:
- 不再用固定阈值把输入简单切成正半轴和负半轴
- 而是根据当前数据分布,自适应地决定激活函数在不同区域的响应强度
可以把它理解成一种带数据感知能力的 PReLU。它会先结合输入的均值、方差做归一化判断,再用一个可学习参数控制负半区保留多少信息。
从直觉上说:
- 如果某个神经元当前输入大多偏大,激活边界就应随之调整
- 如果输入大多偏小,激活函数也不应死板地直接截断
这个技巧对 CTR 模型很有帮助,因为推荐场景里的特征分布往往高度非平稳,激活函数如果能随数据分布自适应变化,通常会比固定 ReLU 更灵活。
所以从工程角度看,DIN 的贡献不只是提出了兴趣激活机制,还包括:
- 在稀疏大规模参数场景下,引入更实用的 mini-batch aware regularization
- 在深层非线性建模里,引入更适合 CTR 分布特点的 DICE 激活函数
7. DIN 的局限
DIN 虽然把“相关兴趣激活”做出来了,但它仍然有两个重要限制:
- 只关注当前候选 item 与历史行为的相关性,没有显式建模兴趣随时间的演化过程
- 历史行为之间彼此独立参与 attention,缺少对序列依赖关系的建模
换句话说,DIN 更像是在回答:
- 哪些历史行为与当前候选 item 更相关
但还没有很好回答:
- 用户兴趣是如何一步步演变到现在的
这也是后续 DIEN 出现的原因。
DIEN
DIEN(Deep Interest Evolution Network)是在 DIN 基础上的进一步发展。它认为,仅仅做“兴趣激活”还不够,因为用户行为本身是一个时间序列,兴趣会不断形成、强化、衰减和转移。
因此,DIEN 想解决的是两个问题:
- 如何从原始行为序列中提取更合理的“兴趣状态”
- 如何建模这些兴趣状态随时间的演化过程
1. 为什么 DIN 还不够
在 DIN 中,历史行为 embedding 基本直接拿来和目标 item 做匹配。这样做默认了一个假设:
- 单个行为 embedding 就足以代表用户在那个时刻的兴趣
但实际并不总是如此。
例如用户连续看了很多手机壳、充电头、数据线,这种连续行为共同表达的可能是“正在为新手机配件做选购”,单独看某一次点击并不能完整体现这一意图。
所以,DIEN 先用序列模型对行为进行编码,把“行为”提升成“兴趣状态”。
2. Interest Extractor Layer
DIEN 的第一层关键结构是 Interest Extractor Layer,通常使用 GRU 来编码用户行为序列:
$$
h_t = \mathrm{GRU}(e_t, h_{t-1})
$$
其中:
- $e_t$ 是第 $t$ 个行为 item 的 embedding
- $h_t$ 是第 $t$ 时刻提取出的兴趣状态
这样一来,$h_t$ 不再只是单个行为的表示,而是融合了前序上下文的信息,更接近“用户此刻的兴趣”。
DIEN 还引入了辅助损失(auxiliary loss)来增强兴趣提取效果。直观理解是:
- 用当前兴趣状态去预测下一个真实行为
- 同时区分真实下一个行为和负采样行为
辅助损失让中间层的兴趣状态拥有更明确的监督信号,而不是只靠最终 CTR 标签反向传播。
3. Interest Evolving Layer
提取出兴趣状态后,DIEN 还需要进一步回答:
- 哪些兴趣状态会持续演化到当前目标相关的兴趣
因此它在第二层又使用了一次基于 GRU 的演化建模,并把目标 item 的注意力信息融入其中。
设从第一层得到兴趣状态序列:
$$
{\mathbf{h}_1,\mathbf{h}_2,\ldots,\mathbf{h}_T}
$$
先计算每个兴趣状态和候选 item 的相关性:
$$
\alpha_t = \mathrm{Att}(\mathbf{h}_t, \mathbf{e}_a)
$$
然后再把这些注意力分数注入到兴趣演化过程里,从而让演化网络更关注与目标相关的兴趣轨迹。
论文中提出了几种 attention 与 GRU 结合的方式,其中最常被提到的是 AUGRU(Attentional Update Gate GRU)。它的直观含义是:
- 如果某个时刻的兴趣状态和目标 item 更相关,就让 GRU 更新得更明显
- 如果相关性较弱,就减小该时刻对最终兴趣表示的影响
4. DIEN 相比 DIN 的提升
DIEN 相比 DIN,实质上多做了两件事:
- 把“历史行为”升级成“兴趣状态序列”
- 把“静态相关性加权”升级成“目标感知的兴趣演化建模”
因此,DIN 更像是:
- 从历史里挑出和当前候选相关的行为
而 DIEN 更像是:
- 先理解用户兴趣是如何形成的
- 再挑出那条与当前目标最相关的兴趣演化路径
5. DIEN 的价值与不足
DIEN 很适合行为序列较长、兴趣变化较快的场景,因为它比 DIN 更强调时间顺序和状态转移。
但它依然有一个局限:
- 它主要把用户行为看成一条线性的时间序列
在很多场景中,用户会在一天内反复切换兴趣,比如上午看零食,中午看耳机,晚上又回来看零食。单纯按时间顺序压成一条长序列,有时并不能很好刻画这种多会话、多兴趣跳转行为。
这就引出了 DSIN。
DSIN
DSIN(Deep Session Interest Network)进一步强调:用户的行为并不只是一个长序列,还天然带有会话(session)结构。
例如在一次连续浏览中,用户可能集中关注某一类商品;而过了一段时间后再打开 App,又进入了另一段新的兴趣会话。把这些行为全都平铺到一条长序列里,可能会稀释局部兴趣模式。
1. 核心动机
DSIN 的出发点是:
- 用户在短时间内的一组连续行为,往往反映一个较稳定的局部兴趣
- 不同 session 之间,兴趣可能发生切换
因此,DSIN 会先把用户行为划分为多个 session,再分别建模 session 内部兴趣与 session 之间的关系。
2. Session 划分
DSIN 通常会根据时间间隔把用户行为切成多个 session。例如:
- 如果两次行为间隔较短,则认为属于同一次浏览会话
- 如果间隔较长,则切到新的 session
于是原始行为序列:
$$
{\mathbf{e}_1,\mathbf{e}_2,\ldots,\mathbf{e}_T}
$$
会被划分为:
$$
\mathcal{S}_1,\mathcal{S}_2,\ldots,\mathcal{S}_K
$$
其中每个 $\mathcal{S}_k$ 表示一个局部会话。
3. Session 内兴趣建模
在每个 session 内,DSIN 会利用 self-attention 或类似机制,对该 session 中的多个行为进行建模,抽取局部兴趣表示。
直观理解是:
- 同一个 session 内的行为通常主题更集中
- 因此更适合在局部范围内做兴趣聚合
如果第 $k$ 个 session 的输出表示记为 $\mathbf{s}_k$,那么最终会得到一个 session 兴趣序列:
$$
{\mathbf{s}_1,\mathbf{s}_2,\ldots,\mathbf{s}_K}
$$
这一步的意义是:先把原始的 item 级行为压缩成 session 级兴趣单元。
4. Session 间演化
得到多个 session 表示后,DSIN 再使用序列模型(如 Bi-LSTM)去建模 session 之间的依赖关系,从而捕捉用户兴趣在多个会话之间的变化。
随后,再结合当前候选 item 做 attention,挑出和目标最相关的 session 兴趣:
$$
\beta_k = \mathrm{Att}(\mathbf{s}_k, \mathbf{e}_a)
$$
再对 session 兴趣加权汇总,得到最终用户表示。
与 DIN 相比,DSIN 不再直接在 item 级别做一次全局 attention;与 DIEN 相比,它也不只是沿单一行为链路建模,而是显式利用了 session 结构。
5. DSIN 适合什么场景
DSIN 特别适合:
- 用户访问具有明显会话特征的场景
- 用户兴趣切换频繁的电商或信息流场景
- 长行为序列下需要降低噪声、突出局部兴趣模式的任务
因为把行为先分 session,可以减少“不同兴趣片段互相干扰”的问题。
6. 从 DIN 到 DIEN 再到 DSIN
这三类模型的演进逻辑可以概括成下面一条主线:
- DIN:解决“历史行为不是等权的”,引入目标感知注意力
- DIEN:解决“兴趣不是静态的”,引入兴趣提取与兴趣演化
- DSIN:解决“行为不是单纯长序列的”,引入会话级兴趣结构
如果从建模粒度来看:
- DIN 主要在 item 行为级别做目标相关建模
- DIEN 在 item 行为级别上进一步建模时间演化
- DSIN 则提升到 session 级别建模局部兴趣和跨会话迁移
7. 总结
DIN 及其后续演化,本质上都围绕一个核心问题展开:
- 如何更真实地表示用户兴趣
早期做法往往把用户兴趣压缩成一个固定向量,而从 DIN 开始,推荐模型逐步意识到:
- 兴趣是和目标相关的
- 兴趣是动态变化的
- 兴趣还可能具有分段、分会话的结构
因此,这条演进路线并不是简单地把模型做深,而是在一步步逼近真实用户行为的生成机制。
在实际工程里如何选择,也可以粗略理解为:
- 如果重点是快速引入目标感知兴趣建模,DIN 是一个经典起点
- 如果更关心兴趣随时间的连续演化,DIEN 更合适
- 如果场景里 session 结构明显,DSIN 往往更有表达力
从这个角度看,DIN 系列模型的价值,不只是提升离线指标,更在于它们把“用户兴趣”从一个静态特征,逐步建模成了一个与目标、时间和会话结构都相关的动态对象。