在推荐、广告和内容分发系统里,我们往往不会只优化一个目标。
以信息流场景为例,平台可能同时关心:
- 点击率(CTR)
- 转化率(CVR)
- 停留时长
- 收藏、加购、分享等互动行为
这些目标都和“用户价值”有关,但又并不完全一致。只做单目标建模会有两个明显问题:
- 每个目标单独训练一套模型,维护成本高,特征利用也不充分
- 不同目标之间本来存在关联,如果完全拆开训练,会损失任务间可以共享的统计规律
因此,多任务学习(Multi-task Learning, MTL)在推荐系统里非常常见。它的基本思想是:
- 用一个模型同时学习多个目标
- 让任务之间共享一部分表示能力
- 又保留各自的个性化建模能力
多目标建模里最经典的一条演化路线,大致可以概括为:
Shared-Bottom:先做最基础的参数共享MMoE:引入专家网络和门控机制,让不同任务学会“按需共享”PLE:进一步缓解任务冲突,把共享信息和任务专属信息分层解耦
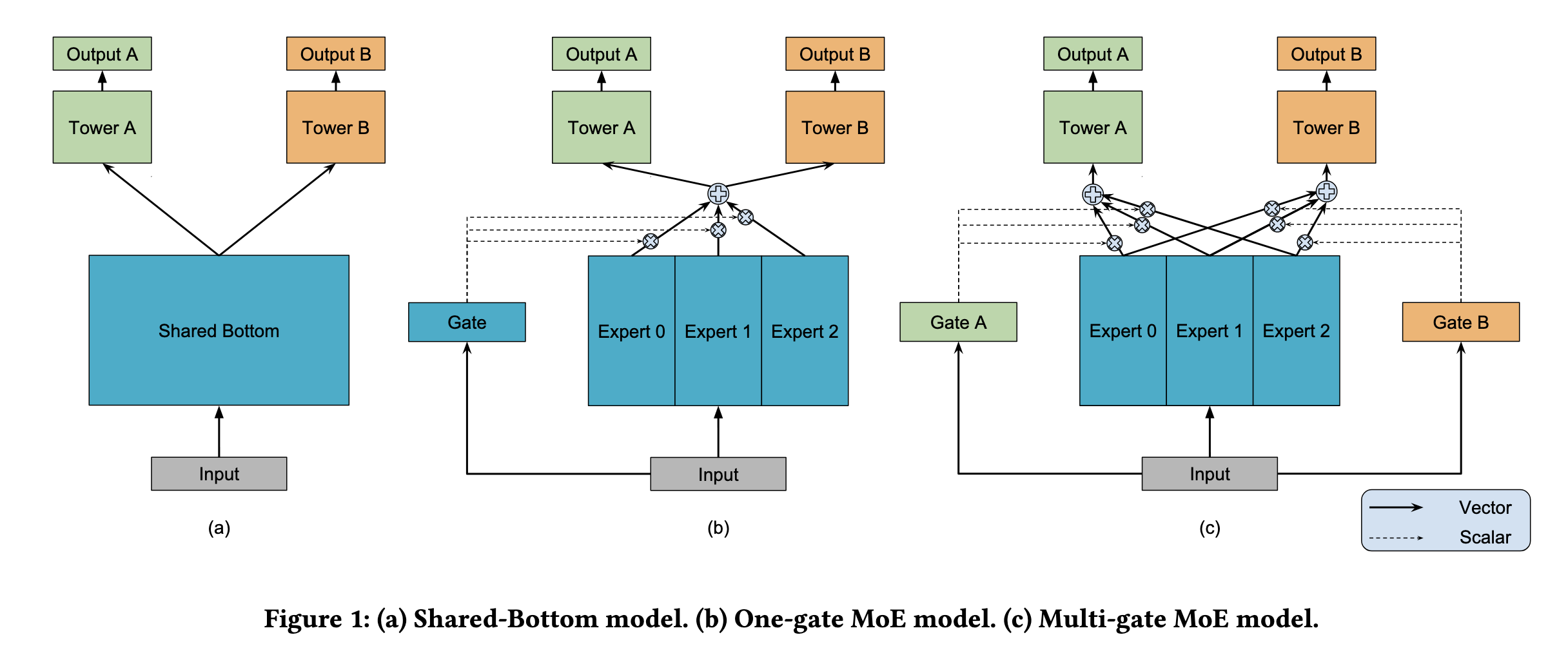
基础架构:Shared-Bottom
Shared-Bottom 是多任务学习里最朴素、也最好理解的结构。
它的做法非常直接:
- 底部使用一套共享的特征抽取网络
- 共享层输出一个公共表示
- 每个任务在顶部再接自己的 tower
- 各任务分别输出自己的预测结果
如果写成形式化表达,可以理解为:
$$
h = f_{shared}(x)
$$
第 $k$ 个任务的输出为:
$$
y_k = f_k(h)
$$
其中:
- $x$ 是输入特征
- $f_{shared}$ 是所有任务共用的底层网络
- $f_k$ 是第 $k$ 个任务自己的输出头
它之所以叫 Shared-Bottom,就是因为“共享”主要发生在底部。
优势
Shared-Bottom 能成为最早期、最广泛使用的多任务结构,不是没有原因的。
- 共享层的存在显著降低了模型总参数量。相比每个目标都单独建模,底层只训练一套网络,训练和部署成本都更低。
- 共享参数天然带来正则化效应。多个任务共同约束底层表示,能够减少单一任务在数据不足时的过拟合风险。
- 当任务之间确实存在相关性时,共享层可以学习到通用模式,从而产生知识迁移,提高泛化能力。
例如在广告场景中:
- CTR 任务会帮助模型学到“用户是否愿意点进来”
- CVR 任务会帮助模型学到“点进来之后是否会成交”
虽然两者不完全一样,但用户、商品、上下文之间的一部分交互规律是可以共享的。
缺陷
Shared-Bottom 的问题也同样明显:它默认所有任务都应该共享同一套底层表示。
这在任务高度相关时通常还可以工作,但一旦任务相关性较弱,甚至存在冲突,就会出现典型的负迁移(negative transfer):
- 某个任务希望强化一类特征
- 另一个任务却希望抑制这类特征
- 共享层被多个目标同时拉扯,最后谁都学不舒服
例如:
- CTR 更关注“是否吸引点击”
- 时长任务更关注“内容是否耐看”
有些标题党内容可能很容易带来点击,却未必能带来长时停留。此时多个目标对共享表示的优化方向并不一致。
所以 Shared-Bottom 的核心问题可以总结为一句话:
- 共享是静态且强制的,无法根据任务差异动态分配表示能力
这也是后续 MMoE 出现的直接动机。
MMoE
MMoE(Multi-gate Mixture-of-Experts)是 Google 在多任务学习场景里提出的一类经典结构。它试图解决的,不是“要不要共享”,而是:
- 哪些知识该共享
- 共享多少
- 不同任务该从哪些专家那里获取信息
相比 Shared-Bottom 的“一刀切共享”,MMoE 把共享改成了可学习的软选择。
OMoE
在正式理解 MMoE 之前,先看一个过渡结构:OMoE(One-gate Mixture-of-Experts)。
OMoE 的核心结构是:
- 底部不再只有一个共享网络,而是放置多个 expert
- 所有 expert 并行接收同一份输入
- 用一个共享 gate 生成权重
- 将多个 expert 的输出加权汇总后,再送给不同任务头
设有 $n$ 个 expert,第 $i$ 个 expert 输出为:
$$
e_i(x)
$$
共享 gate 生成权重:
$$
g(x) = \mathrm{softmax}(W_g x)
$$
则融合表示可写成:
$$
h = \sum_{i=1}^{n} g_i(x)e_i(x)
$$
然后再由不同任务塔做预测。
OMoE 比 Shared-Bottom 更灵活,因为:
- 不再强迫所有任务只使用同一个底层表征
- 模型可以把不同模式分散到不同 expert 中
但它仍然有一个很大的限制:
- 所有任务共享同一个 gate
也就是说,虽然 expert 变多了,但“如何组合这些 expert”仍然是一套统一策略。这意味着不同任务最终看到的仍是同一种专家加权结果。
所以 OMoE 只解决了“共享网络容量不足”的问题,却没有真正解决“任务对共享知识需求不同”的问题。
MMoE 架构及原理
MMoE 相比 OMoE 的关键变化只有一句话:
- 每个任务都有自己独立的 gate
整体结构变成:
- 底部有多个共享 expert
- 每个任务都拥有一个自己的 gating network
- 不同任务分别对同一组 expert 进行加权组合
- 每个任务再接自己的 tower 输出预测结果
设共有 $n$ 个 expert,第 $k$ 个任务的 gate 输出为:
$$
g^{(k)}(x) = \mathrm{softmax}(W^{(k)}_g x)
$$
则第 $k$ 个任务获得的输入表示为:
$$
h^{(k)} = \sum_{i=1}^{n} g^{(k)}_i(x)e_i(x)
$$
最后第 $k$ 个任务输出:
$$
y_k = f_k(h^{(k)})
$$
这个变化看似不大,但本质上完成了从“统一共享”到“按任务路由”的转变。
直观理解 MMoE,可以把 expert 看成一组不同能力的老师:
- 有的 expert 更擅长建模点击模式
- 有的 expert 更擅长建模转化倾向
- 有的 expert 更擅长建模长时兴趣
而每个任务自己的 gate,决定它更愿意听哪些老师的意见。
MMoE 相比 Shared-Bottom 的改进
MMoE 的优势主要体现在三个方面。
- 共享不再是硬性的,而是软性的。不同任务可以根据自身需要,从多个 expert 中动态组合信息。
- expert 之间天然形成某种功能分化。即使没有显式标注,训练过程中也可能出现“某些 expert 更偏向某类任务模式”的现象。
- 当任务相关性复杂、部分共享但又不完全重叠时,MMoE 往往比 Shared-Bottom 更稳健。
从经验上看,任务越多、任务差异越大,MMoE 相比 Shared-Bottom 的优势通常越明显。
MMoE 的局限
虽然 MMoE 比 Shared-Bottom 强很多,但它并没有彻底消灭负迁移。
主要原因有两个。
第一,expert 本身仍然是所有任务共享的。
也就是说,即便 gate 不同,底层 expert 参数还是被多个任务共同训练。如果任务冲突很强,expert 仍然可能学成“折中结果”。
第二,门控决策负担很重。
gate 需要同时完成两件事:
- 判断当前样本更适合走哪些 expert
- 间接协调不同任务之间的冲突
如果 expert 没有形成足够清晰的职责分工,gate 的选择空间就会变得混乱。最终模型可能出现:
- 多个任务都偏向同一批 expert
- 某些 expert 长期得不到充分训练
- 任务冲突被转移到 gate 和 shared expert 上,但没有真正被拆开
换句话说,MMoE 让“共享”变聪明了,但共享和专属之间的边界仍然不够清楚。
这正是 PLE 想进一步解决的问题。
PLE
PLE(Progressive Layered Extraction)可以看作是对 MMoE 的进一步结构化改造。它的核心判断是:
- MMoE 之所以仍会出现负迁移,不仅是因为共享方式不够灵活
- 更因为“共享知识”和“任务私有知识”没有被显式拆开
因此,PLE 希望把信息流分成两类:
- 共享信息
- 任务专属信息
并通过逐层提取(progressive layered extraction)的方式,让二者既能交互,又不过度混杂。
MMoE 负迁移未根除,门控决策负担重,PLE 正是在这个背景下提出的。
CGC结构
PLE 的基础模块叫 CGC(Customized Gate Control)。
一个 CGC 层通常包含两类 expert:
- shared experts:为所有任务提供公共知识
- task-specific experts:只服务于某一个任务
然后,每个任务自己的 gate 不再对“全体 expert”做无差别选择,而是从:
- 本任务的 task-specific experts
- shared experts
这两部分中进行加权组合。
与此同时,共享分支自己也会有一个 gate,用来聚合:
- 所有任务的专属 expert
- shared experts
从而形成下一层共享表示。
这套机制的关键价值,在于它把“所有 expert 都放在一个池子里竞争”改成了“共享池 + 专属池”的显式分层。
1. 专家职责强制分离
这是 PLE 相比 MMoE 最重要的一点。
在 MMoE 中,所有 expert 理论上都服务于所有任务,最终是否形成分工,主要依赖训练过程的自发演化。
而在 PLE 中,模型结构直接规定:
- 有些 expert 就是公共专家
- 有些 expert 就是任务私有专家
这样做的好处是:
- 公共模式可以沉淀在 shared experts 中
- 任务特有模式可以沉淀在 task-specific experts 中
- 不必把“共享多少、私有多少”都压给 gate 自己去学
也就是说,PLE 用结构先验主动帮助模型做职责划分。
2. 任务专属门控的输入限制
另一个关键点是,任务 gate 的可选范围被限制了。
对于第 $k$ 个任务,它不会像 MMoE 一样面对所有 expert,而只会从下面两类中选择:
- 第 $k$ 个任务自己的专属 experts
- shared experts
这意味着:
- 任务不会直接去读取别的任务的私有 expert
- 跨任务共享必须通过 shared experts 这一“公共通道”完成
这种限制非常重要,因为它减少了无序的信息串扰。
可以把它理解为:
- MMoE 像一个开放式大群,所有任务都能直接找所有 expert
- PLE 更像有公共会议室,也有每个任务自己的办公室
共享问题去公共会议室讨论,私有问题留在各自办公室解决。
PLE架构及原理
PLE 往往不是只堆一层 CGC,而是堆叠多层,形成 progressive layered extraction。
它的基本流程可以理解为:
- 输入特征进入第一层 CGC
- 每个任务分支和共享分支分别得到自己的表示
- 这些表示继续送入下一层 CGC
- 随着层数加深,共享信息与任务专属信息被逐步提炼
- 最后每个任务分支接自己的 tower 输出结果
如果从建模逻辑上理解,PLE 做的是一种“逐层去混叠”:
- 底层允许较多共享,因为原始特征里确实有大量共性
- 越往上走,任务差异越明显,专属分支承担更多个性化建模
这比只在单层上做一次专家选择更细致,也更符合多任务学习中“底层偏通用、高层偏任务化”的经验规律。
PLE 的优势
PLE 在工业界受欢迎,主要是因为它比 MMoE 更稳定。
- 显式区分共享专家和任务专家,能更有效缓解负迁移。
- gate 的选择空间被约束后,决策难度下降,训练更容易稳定。
- 多层 CGC 让共享信息和私有信息可以逐步分化,而不是一次性硬切。
- 在任务相关但不完全一致的场景中,通常比 Shared-Bottom 和 MMoE 更鲁棒。
特别是在推荐和广告系统中,像:
- CTR
- CVR
- 完播率
- 停留时长
- 互动率
这些目标往往既有共性,又各自强调不同的行为结果,PLE 通常会比简单共享结构更合适。
PLE 的代价
当然,PLE 也不是没有成本。
- 结构更复杂,参数量和训练成本通常高于 Shared-Bottom。
- 超参数更多,例如 shared experts 数量、task-specific experts 数量、CGC 层数等,调参复杂度更高。
- 当任务非常少、而且相关性很强时,PLE 的收益未必足以覆盖其复杂度。
因此是否使用 PLE,本质上还是一个工程权衡:
- 任务越多
- 目标差异越大
- 负迁移越明显
PLE 的价值通常越大。
总结
如果把这几种结构放在同一条演进线上,可以这样理解:
1. Shared-Bottom
- 假设所有任务共享同一套底层表示
- 优点是简单、高效、易落地
- 缺点是容易受到负迁移影响
2. MMoE
- 通过多个 expert 和任务独立 gate,实现按任务动态共享
- 比 Shared-Bottom 更灵活
- 但 expert 仍是全共享的,任务冲突没有被彻底拆解
3. PLE
- 在 MMoE 基础上进一步显式区分共享专家和任务专家
- 通过分层提取逐步解耦共享信息与私有信息
- 通常在复杂多目标场景下表现更稳
所以从本质上说,这三者是在回答同一个问题:
- 多个任务到底应该如何共享表示能力
它们给出的答案分别是:
- Shared-Bottom:大家先共用一套底层再说
- MMoE:共享可以,但要让不同任务自己决定怎么用
- PLE:共享和私有都要有,而且要在结构上明确分开
在真实业务里,没有哪个结构对所有问题都最优。更合理的做法通常是根据场景判断:
- 如果任务少且高度相关,Shared-Bottom 可能已经足够
- 如果任务关系复杂,MMoE 往往是一个很好的起点
- 如果负迁移明显、目标差异较大,PLE 通常更值得尝试
理解这条演化链条,比死记某个结构图更重要。因为多目标建模的核心从来不是“哪篇论文最火”,而是:
- 如何在共享收益和任务冲突之间找到合适的平衡